typefile
ID
s24aeawxasrgj0cgkzabtj53rc
Status
Succeeded
Source
Web
Hardware
A40 (Large)
Total duration
Created
by janghaludu
Webhook
–
Input
- prompt
- Reply in json format with the following keys - containsLines : True or False, colorsOfLines: array of str, numberOfLines: int, numberOfIntersectionPointsBetweenLines: inttypetext
- top_p
- 1default1typenumeric-rangevalue typenumbermaximum1
- temperature
- 0.2default0.2typenumericvalue typenumber
- max_tokens
- 1024default1024typenumericvalue typeinteger
- history
- typearrayvalue typestring
{
"history": [],
"image": "https://replicate.delivery/pbxt/LFOkHr2gGAdPNIanHgR9W4NpYaMSyL605eBBtmTIhZ2ZYu9F/Screenshot%202024-07-11%20at%208.56.55%20AM.png",
"max_tokens": 1024,
"prompt": "Reply in json format with the following keys - containsLines : True or False, colorsOfLines: array of str, numberOfLines: int, numberOfIntersectionPointsBetweenLines: int",
"temperature": 0.2,
"top_p": 1
}Install Replicate’s Node.js client library:
npm install replicate
Set the
REPLICATE_API_TOKEN environment variable:export REPLICATE_API_TOKEN=r8_eo7**********************************
This is your API token. Keep it to yourself.
Import and set up the client:
import Replicate from "replicate";
const replicate = new Replicate({
auth: process.env.REPLICATE_API_TOKEN,
});
Run yorickvp/llava-v1.6-mistral-7b using Replicate’s API. Check out the model's schema for an overview of inputs and outputs.
const output = await replicate.run(
"yorickvp/llava-v1.6-mistral-7b:19be067b589d0c46689ffa7cc3ff321447a441986a7694c01225973c2eafc874",
{
input: {
image: "https://replicate.delivery/pbxt/LFOkHr2gGAdPNIanHgR9W4NpYaMSyL605eBBtmTIhZ2ZYu9F/Screenshot%202024-07-11%20at%208.56.55%20AM.png",
max_tokens: 1024,
prompt: "Reply in json format with the following keys - containsLines : True or False, colorsOfLines: array of str, numberOfLines: int, numberOfIntersectionPointsBetweenLines: int",
temperature: 0.2,
top_p: 1
}
}
);
console.log(output);
To learn more, take a look at the guide on getting started with Node.js.
Install Replicate’s Python client library:
pip install replicate
Set the
REPLICATE_API_TOKEN environment variable:export REPLICATE_API_TOKEN=r8_eo7**********************************
This is your API token. Keep it to yourself.
Import the client:
import replicate
Run yorickvp/llava-v1.6-mistral-7b using Replicate’s API. Check out the model's schema for an overview of inputs and outputs.
output = replicate.run(
"yorickvp/llava-v1.6-mistral-7b:19be067b589d0c46689ffa7cc3ff321447a441986a7694c01225973c2eafc874",
input={
"image": "https://replicate.delivery/pbxt/LFOkHr2gGAdPNIanHgR9W4NpYaMSyL605eBBtmTIhZ2ZYu9F/Screenshot%202024-07-11%20at%208.56.55%20AM.png",
"max_tokens": 1024,
"prompt": "Reply in json format with the following keys - containsLines : True or False, colorsOfLines: array of str, numberOfLines: int, numberOfIntersectionPointsBetweenLines: int",
"temperature": 0.2,
"top_p": 1
}
)
# The yorickvp/llava-v1.6-mistral-7b model can stream output as it's running.
# The predict method returns an iterator, and you can iterate over that output.
for item in output:
# https://replicate.com/yorickvp/llava-v1.6-mistral-7b/api#output-schema
print(item, end="")
To learn more, take a look at the guide on getting started with Python.
Set the
REPLICATE_API_TOKEN environment variable:export REPLICATE_API_TOKEN=r8_eo7**********************************
This is your API token. Keep it to yourself.
Run yorickvp/llava-v1.6-mistral-7b using Replicate’s API. Check out the model's schema for an overview of inputs and outputs.
curl -s -X POST \
-H "Authorization: Bearer $REPLICATE_API_TOKEN" \
-H "Content-Type: application/json" \
-H "Prefer: wait" \
-d $'{
"version": "yorickvp/llava-v1.6-mistral-7b:19be067b589d0c46689ffa7cc3ff321447a441986a7694c01225973c2eafc874",
"input": {
"image": "https://replicate.delivery/pbxt/LFOkHr2gGAdPNIanHgR9W4NpYaMSyL605eBBtmTIhZ2ZYu9F/Screenshot%202024-07-11%20at%208.56.55%20AM.png",
"max_tokens": 1024,
"prompt": "Reply in json format with the following keys - containsLines : True or False, colorsOfLines: array of str, numberOfLines: int, numberOfIntersectionPointsBetweenLines: int",
"temperature": 0.2,
"top_p": 1
}
}' \
https://api.replicate.com/v1/predictions
To learn more, take a look at Replicate’s HTTP API reference docs.
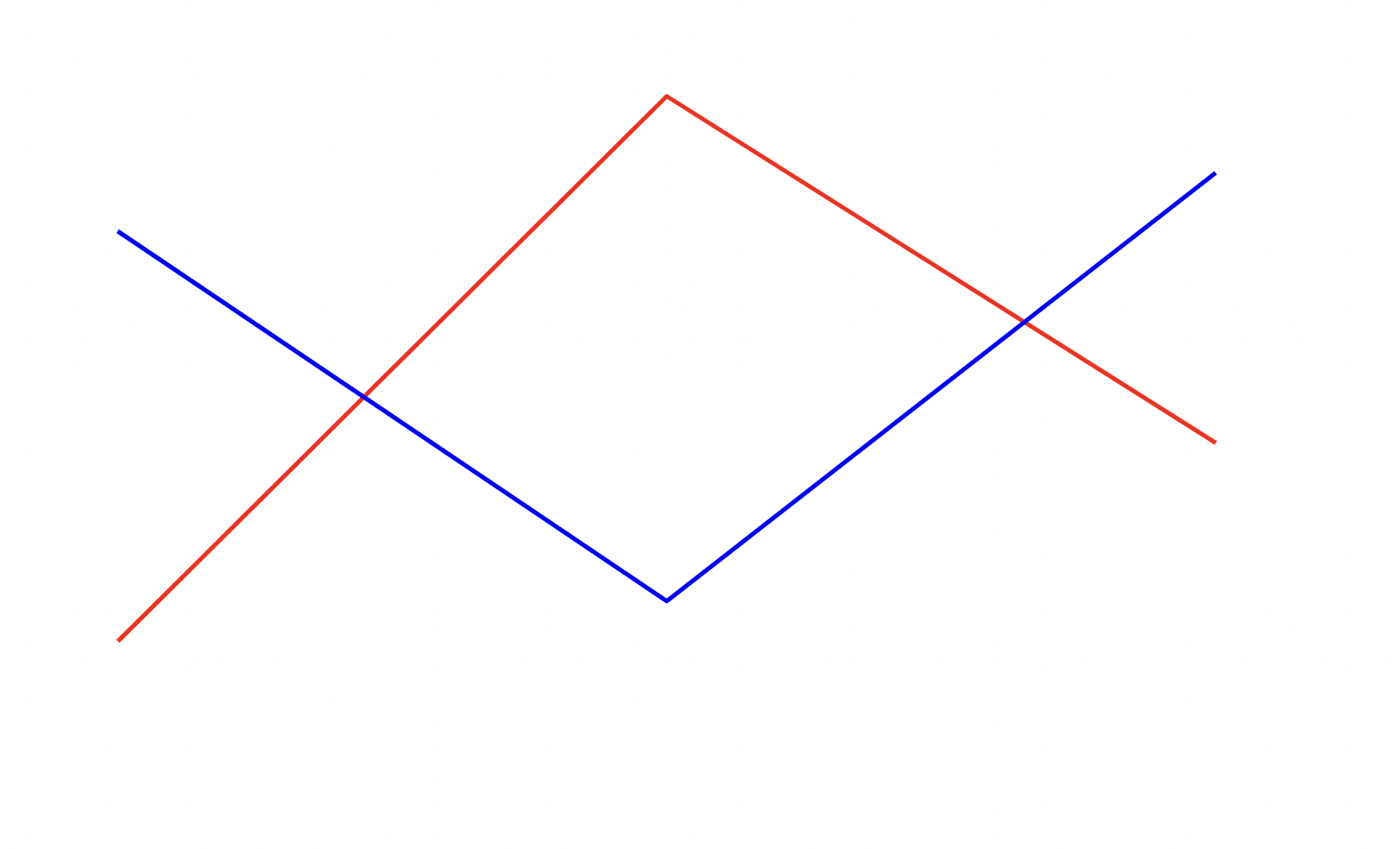
Output
```json
{
"containsLines": true,
"colorsOfLines": ["red", "blue"],
"numberOfLines": 4,
"numberOfIntersectionPointsBetweenLines": 2
}
``` {
"id": "s24aeawxasrgj0cgkzabtj53rc",
"model": "yorickvp/llava-v1.6-mistral-7b",
"version": "19be067b589d0c46689ffa7cc3ff321447a441986a7694c01225973c2eafc874",
"input": {
"history": [],
"image": "https://replicate.delivery/pbxt/LFOkHr2gGAdPNIanHgR9W4NpYaMSyL605eBBtmTIhZ2ZYu9F/Screenshot%202024-07-11%20at%208.56.55%20AM.png",
"max_tokens": 1024,
"prompt": "Reply in json format with the following keys - containsLines : True or False, colorsOfLines: array of str, numberOfLines: int, numberOfIntersectionPointsBetweenLines: int",
"temperature": 0.2,
"top_p": 1
},
"logs": "The attention mask and the pad token id were not set. As a consequence, you may observe unexpected behavior. Please pass your input's `attention_mask` to obtain reliable results.\nSetting `pad_token_id` to `eos_token_id`:2 for open-end generation.",
"output": [
"```json\n",
"{\n",
" ",
"\"containsLines\": ",
"true,\n",
" ",
"\"colorsOfLines\": ",
"[\"red\", ",
"\"blue\"],\n",
" ",
"\"numberOfLines\": ",
"4,\n",
" ",
"\"numberOfIntersectionPointsBetweenLines\": ",
"2\n",
"}\n",
"``` "
],
"data_removed": false,
"error": null,
"source": "web",
"status": "succeeded",
"created_at": "2024-07-11T03:27:09.654Z",
"started_at": "2024-07-11T03:27:09.689137Z",
"completed_at": "2024-07-11T03:27:12.533752Z",
"urls": {
"cancel": "https://api.replicate.com/v1/predictions/s24aeawxasrgj0cgkzabtj53rc/cancel",
"get": "https://api.replicate.com/v1/predictions/s24aeawxasrgj0cgkzabtj53rc",
"stream": "https://streaming-api.svc.us.c.replicate.net/v1/streams/k2a347dg4q275be4grjiw2xqhw6v73edhqqqedknea3sb76zba3q",
"web": "https://replicate.com/p/s24aeawxasrgj0cgkzabtj53rc"
},
"metrics": {
"predict_time": 2.844614506,
"total_time": 2.879752
}
}