How to run Mistral 7B with an API
Mistral 7B is a new open-source language model from Mistral AI that outperforms not just all other 7 billion parameter language models, but also Llama 2 13B and sometimes even the original Llama 34B. It approaches CodeLlama 7B performance on coding tasks.
There’s also Mistral 7B Instruct, a model fine-tuned for chat completions. It’s comparable to Llama 2 13B fine-tuned for chat.
@a16z-infra pushed Mistral 7B and Mistral 7B Instruct to Replicate. Let’s take a look at what makes Mistral 7B stand out, then we’ll show you how to run it with an API.
It has more recent training data
Mistral 7B’s training data cutoff was sometime in 2023, so it knows about things that happened this year.
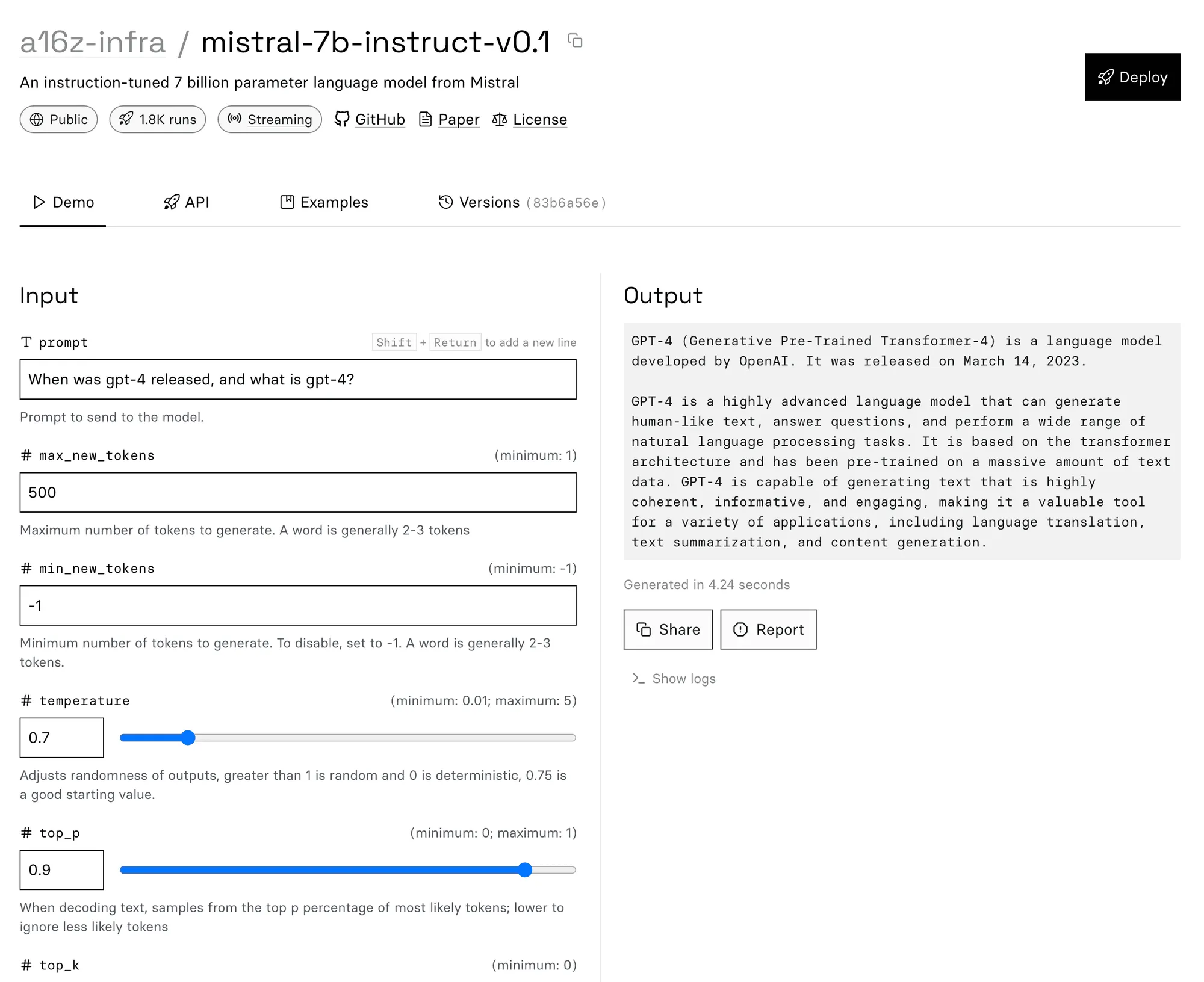
Keep in mind that Mistral is just a language model so it’s prone to hallucination. Even though it was trained on data up to 2023, that doesn’t mean it recites those things reliably. 😃
It’s faster
Mistral 7B uses grouped-query attention and sliding window attention to improve speed and use less memory. The Mistral team found that their usage of sliding window attention doubled inference speed on a 16k token sequence length. For more detail on these techniques, as well as an in-depth comparison of Mistral 7B and Llama, check out Mistral AI’s launch blog post.
It’s good at writing code
We’ve found Mistral 7B writes codes well, and with a bit of flair to boot. Here’s Mistral writing a Python function to compute the Fibonacci sequence while talking like a pirate:
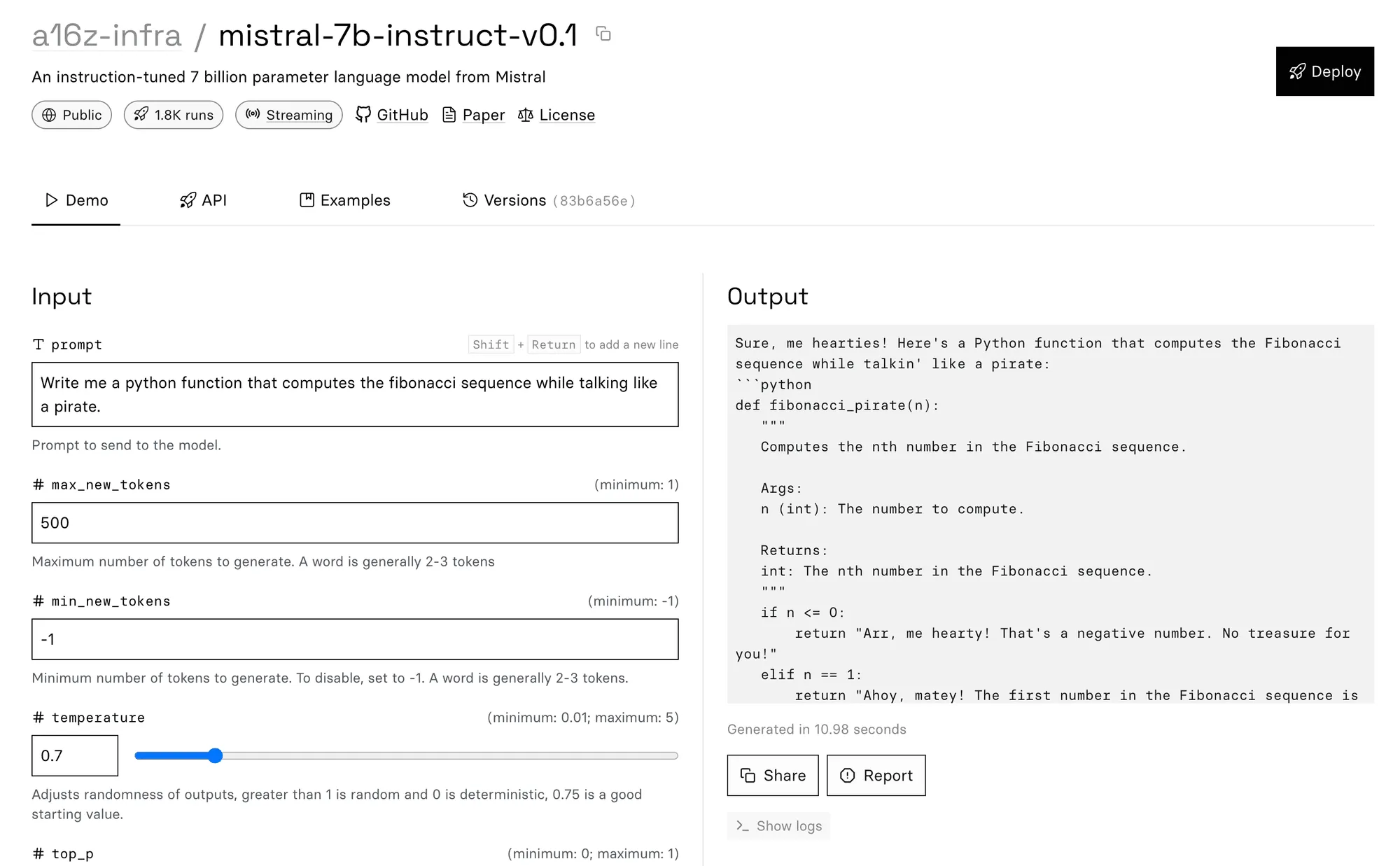
And, as a final taste of its capabilities, it does a surprisingly good job of generating recipes, even with unorthodox ingredients:
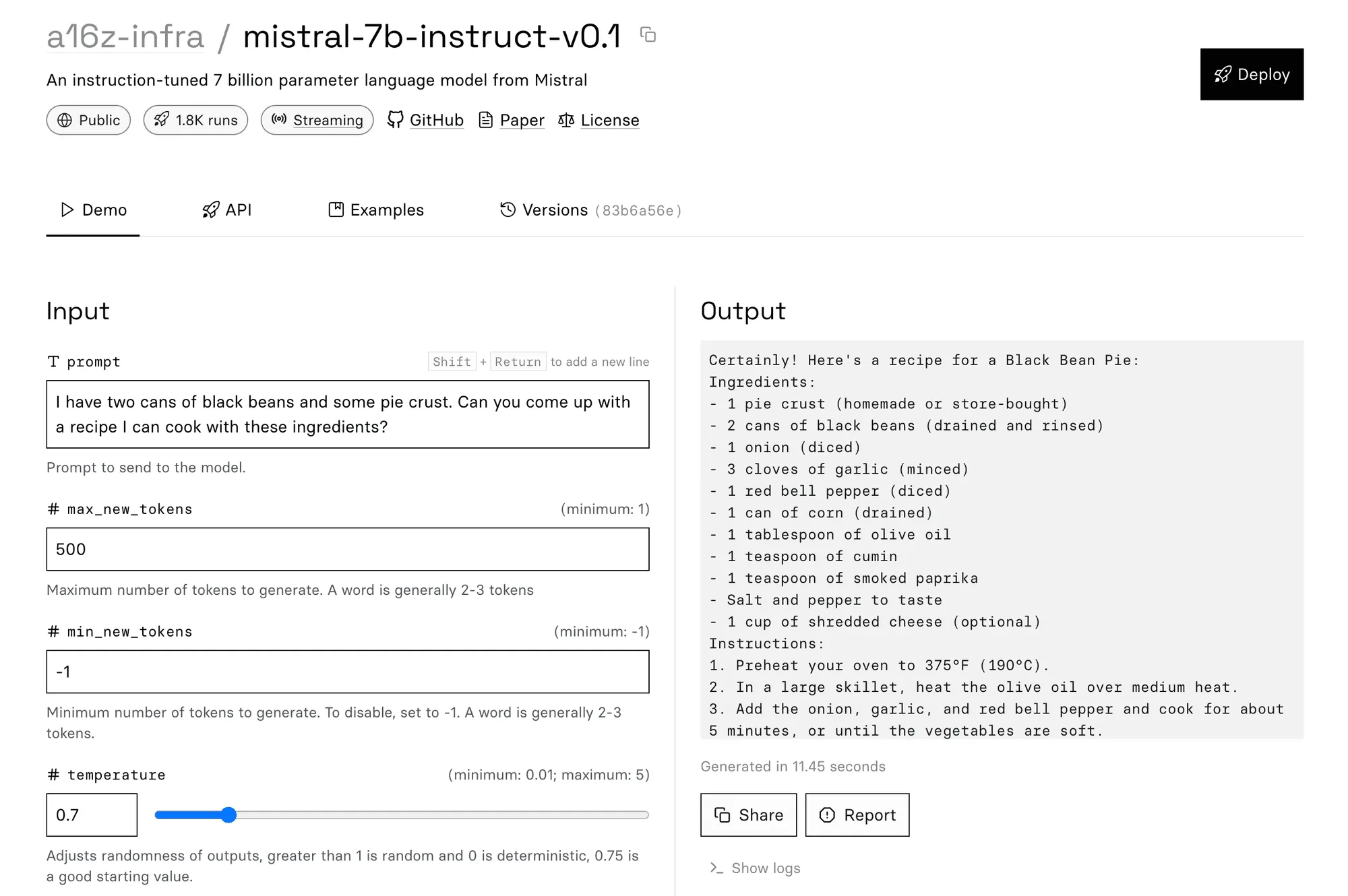
How to run Mistral 7B with an API
Mistral 7B is on Replicate and you can run it in the cloud with one line of code.
You can run it with our JavaScript client:
import Replicate from "replicate";
const replicate = new Replicate({
auth: process.env.REPLICATE_API_TOKEN,
});
const input = {
prompt:
"Write a poem about open source machine learning in the style of Mary Oliver.",
};
for await (const event of replicate.stream(
"mistralai/mistral-7b-instruct-v0.2",
{
input,
}
)) {
process.stdout.write(event.toString());
}Or, our Python client:
import replicate
# The mistralai/mistral-7b-instruct-v0.2 model can stream output as it's running.
for event in replicate.stream(
"mistralai/mistral-7b-instruct-v0.2",
input={"prompt": "how are you doing today?"},
):
print(str(event), end="")Or, you can call the HTTP API directly with tools like cURL:
curl -s -X POST \
-H "Authorization: Bearer $REPLICATE_API_TOKEN" \
-H "Content-Type: application/json" \
-H "Prefer: wait" \
-d $'{
"input": {
"prompt": "how are you doing today? "
}
}' \
https://api.replicate.com/v1/models/mistralai/mistral-7b-instruct-v0.2/predictionsYou can also run Mistral using other Replicate client libraries for Go, Swift, Elixir, and others.
Next steps
- Take a look at a16z-infra/mistral-7b-v0.1 and a16z-infra/mistral-7b-instruct-v0.1 on Replicate.
- Mistral 7B fine tunes are also gathering steam. nateraw/mistral-7b-openorca was fine-tuned on the Open Orca dataset for chat.
- 🥊 Want to compare Mistral to Llama? We built a site called LLM Boxing that pits languages models against each other in a blind test, and lets you decide which model is better. At the time of posting this, Mistral 7b Instruct has a lead on Llama 2 13b Chat of 3985 to 3335. Will that lead hold? Check it out and see for yourself.