
daanelson / cpu-fake-trainer
daanelson / big-flux-dev

daanelson / dev-test

daanelson / flux-fill-dev-big
Image inpainting with flux

daanelson / test-flux-train
daanelson / sdxl-tune-test

daanelson / speedy-sdxl-test
SDXL, but faster

daanelson / training-2

daanelson / whisper-train-preprocessor
Dataset Preprocessing code for Whisper Fine-Tuning

daanelson / whisperx
Accelerated transcription of audio using WhisperX

daanelson / speedy-stable-diffusion-inpainting
Filling in images quickly with Stable Diffusion and AITemplate
daanelson / whisper-jax-hindi

daanelson / whisper-tune
A fine-tuneable version of whisper

daanelson / sd-21-fp16
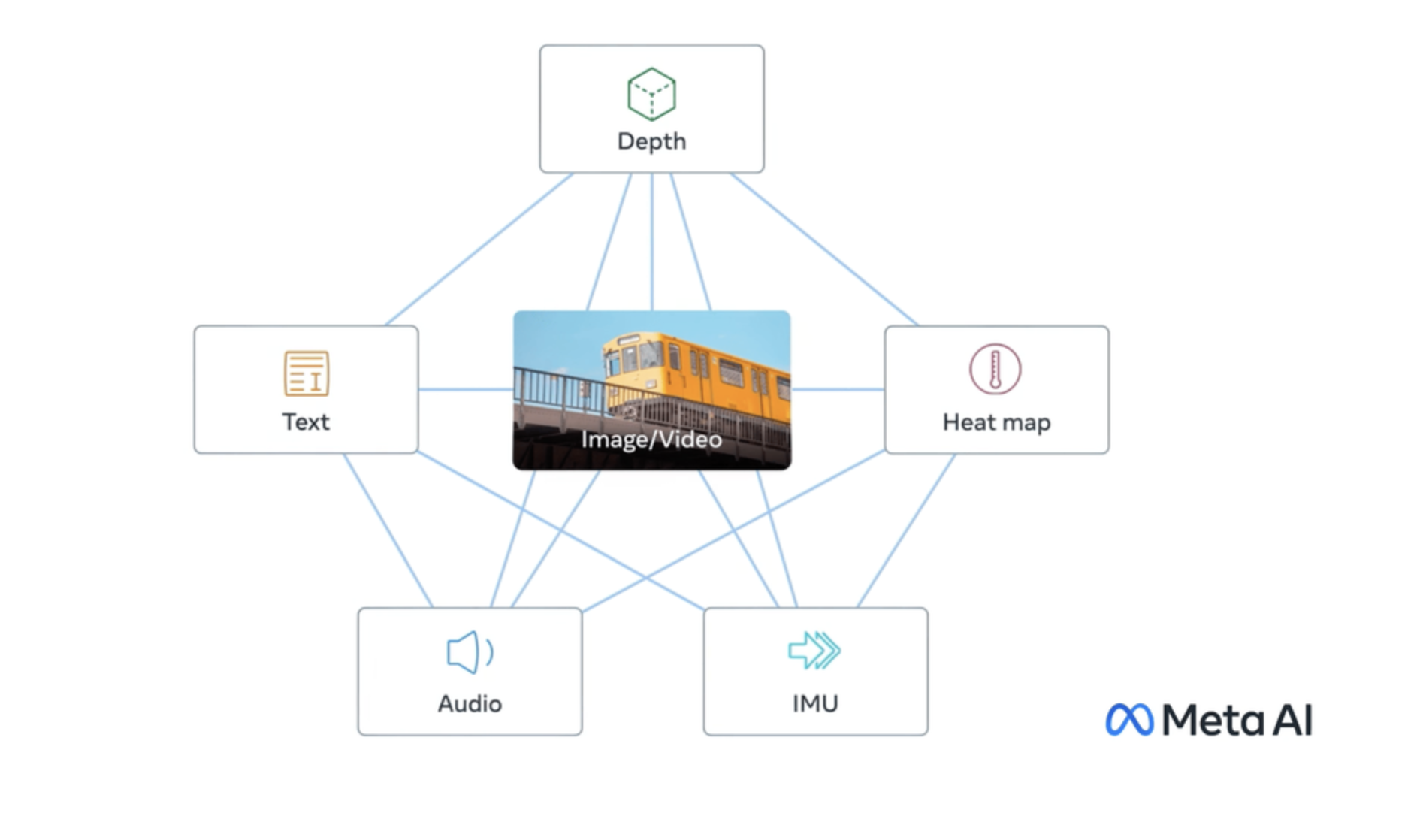
daanelson / imagebind
A model for text, audio, and image embeddings in one space

daanelson / minigpt-4
A model which generates text in response to an input image and prompt.
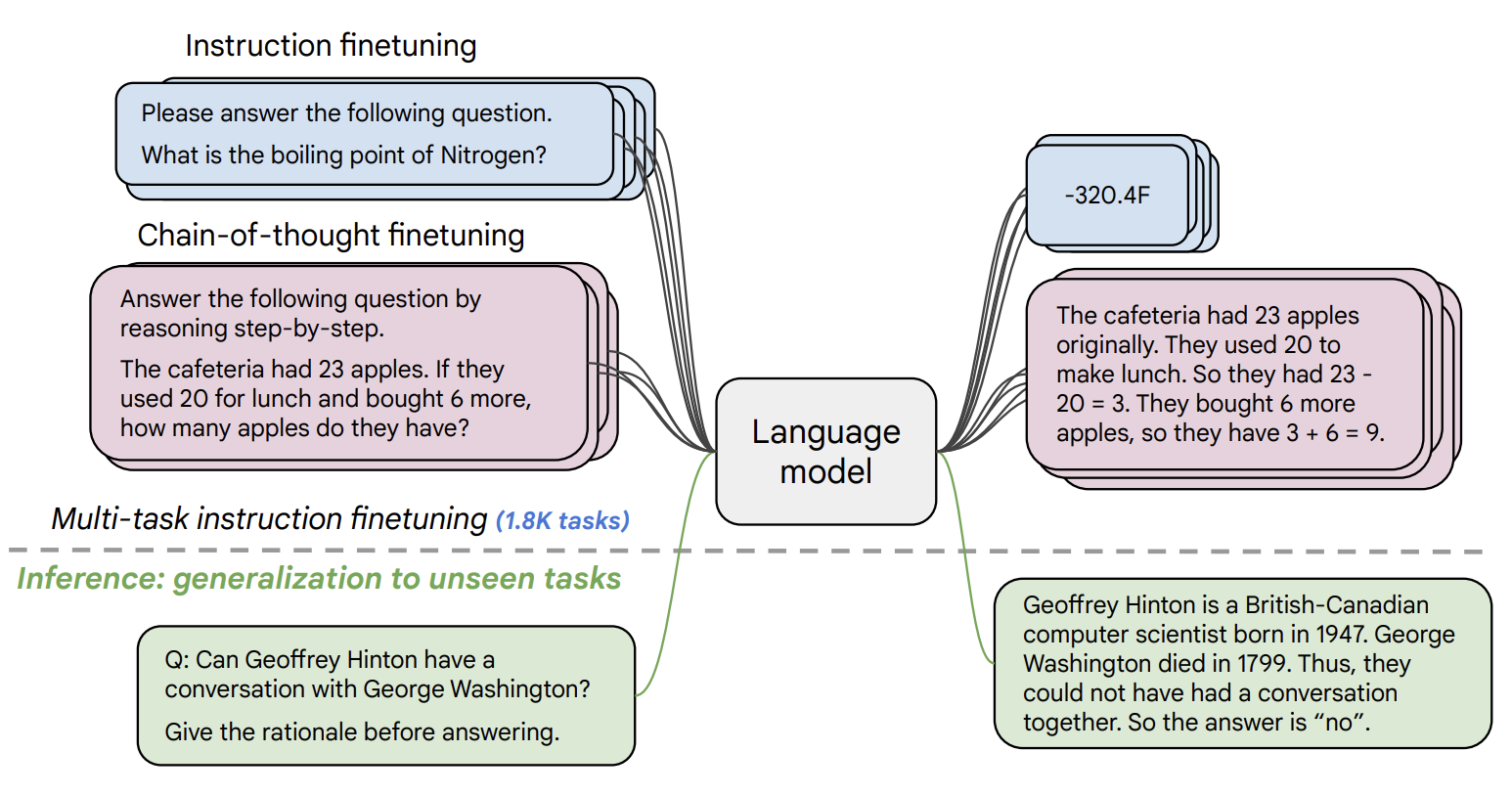
daanelson / flan-t5-large
A language model for tasks like classification, summarization, and more.
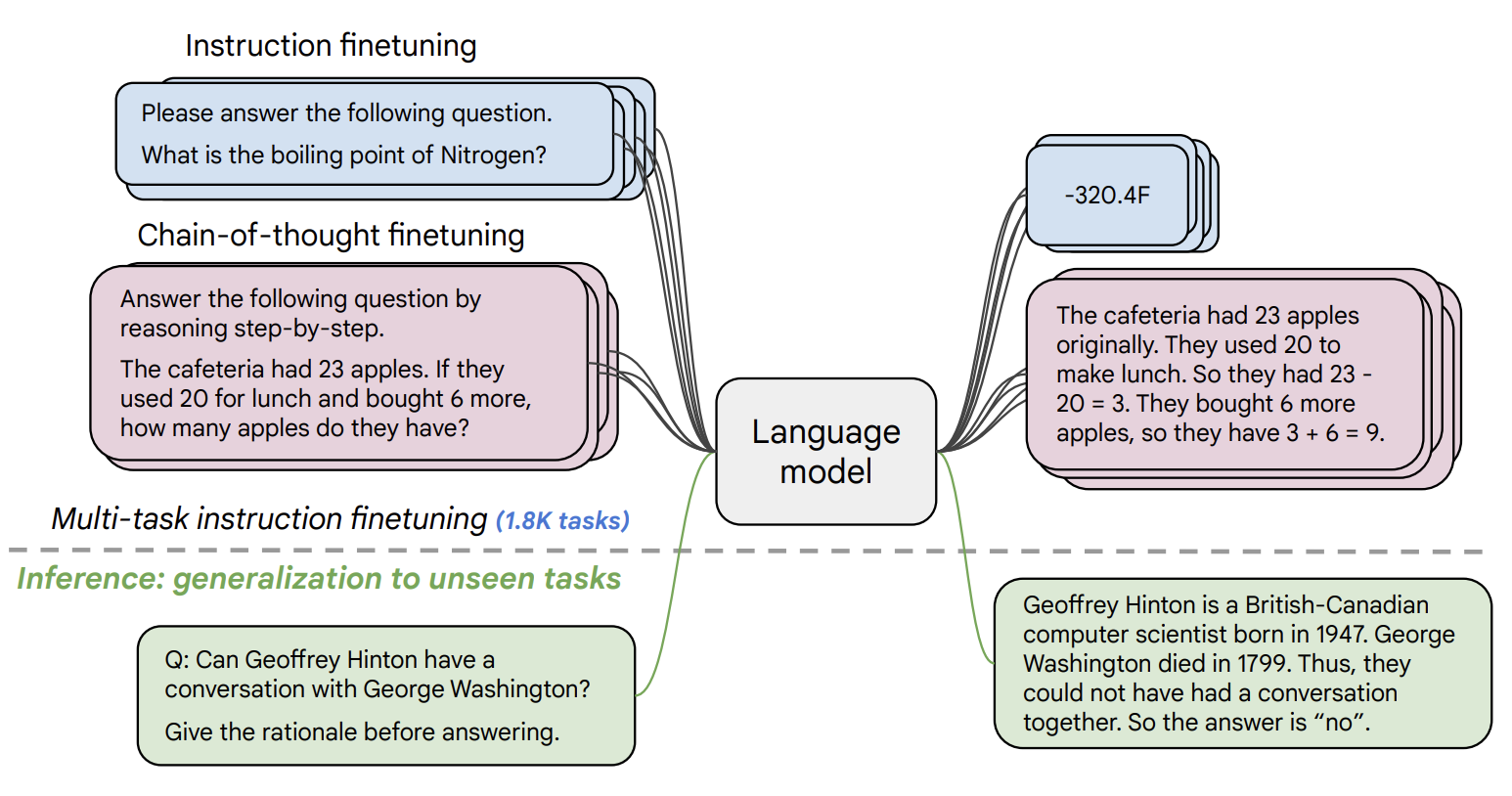
daanelson / flan-t5-base
A small model for language tasks like classification, summarization, and more.

daanelson / real-esrgan-a100
Real-ESRGAN for image upscaling on an A100

daanelson / gfpgan-1-4
daanelson / gfpgan-test
Face restoration and 2x upscaling
daanelson / swin2sr-speedy
daanelson / whisper-sandbox
Test model for whisper improvements

daanelson / mixture-of-diffusers
Generate an image by specifying a different text prompt for each region

daanelson / plug_and_play_image_translation
Edit an image using features from diffusion models

daanelson / stable-diffusion-speed-lab
Stable Diffusion, accelerated

daanelson / attend-and-excite
Attention-Based Semantic Guidance for Text-to-Image Diffusion Models

daanelson / stable-diffusion-long-prompts
img2img Stable Diffusion, but with longer prompts

daanelson / yolox
High performance and lightweight object detection models

daanelson / some-upscalers
Some 4x esrgan upscalers

daanelson / motion_diffusion_model
A diffusion model for generating human motion video from a text prompt