Recommended Models

 rafaelgalle/whisper-diarization-advanced
rafaelgalle/whisper-diarization-advancedUltra-fast, customizable speech-to-text and speaker diarization for noisy, multi-speaker audio. Includes advanced noise reduction, stereo channel support, and flexible audio preprocessing—ideal for call centers, meetings, and podcasts.
Updated 2 weeks, 5 days ago
597.5K runs

 thomasmol/whisper-diarization
thomasmol/whisper-diarization⚡️ Blazing fast audio transcription with speaker diarization | Whisper Large V3 Turbo & pyannote 4.0 community-1 | word & sentence level timestamps | prompt
Updated 1 month, 1 week ago
8.7M runs

 victor-upmeet/whisperx
victor-upmeet/whisperxAccelerated transcription, word-level timestamps and diarization with whisperX large-v3
Updated 2 months ago
8.3M runs

 collectiveai-team/speaker-diarization-3
collectiveai-team/speaker-diarization-3Segments an audio recording based on who is speaking
Updated 2 years, 4 months ago
6.9K runs

 vaibhavs10/incredibly-fast-whisper
vaibhavs10/incredibly-fast-whisperwhisper-large-v3, incredibly fast, powered by Hugging Face Transformers! 🤗
Updated 2 years, 5 months ago
38.7M runs

 awerks/whisperx
awerks/whisperxFast automatic speech recognition (70x realtime with large-v2) with word-level timestamps and speaker diarization.
Updated 2 years, 10 months ago
82.1K runs
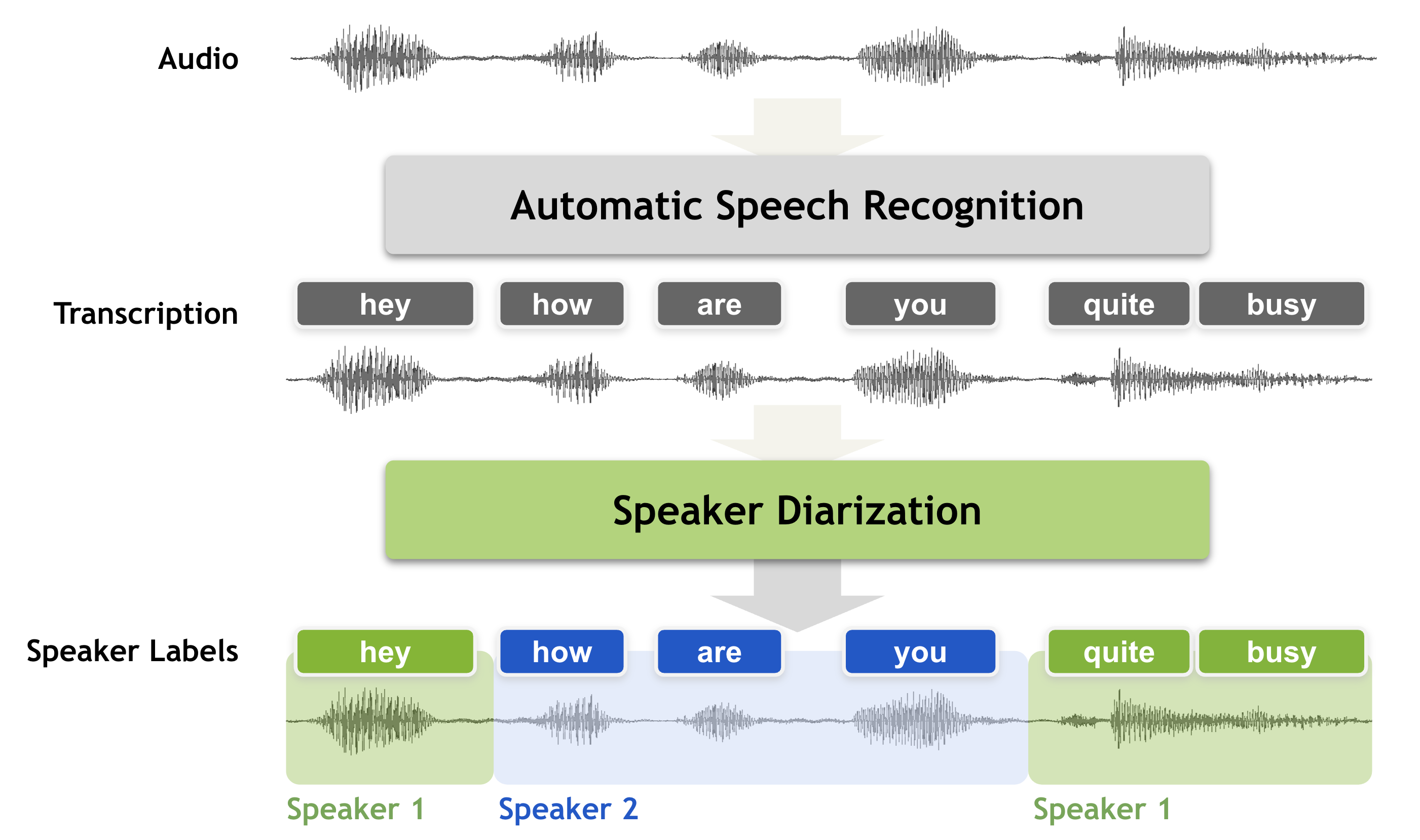
 sabuhigr/sabuhi-model
sabuhigr/sabuhi-modelWhisper AI with channel separation and speaker diarization
Updated 2 years, 11 months ago
25.5K runs
 lucataco/speaker-diarization
lucataco/speaker-diarizationSegments an audio recording based on who is speaking (on A100)
Updated 2 years, 11 months ago
13.6K runs

 meronym/speaker-transcription
meronym/speaker-transcriptionWhisper transcription plus speaker diarization
Updated 3 years, 2 months ago
28.5K runs