
Readme
L3DAS22 challenge baselines demo
This page supports the L3DAS22 challenge and is aimed at demonstrating our baseline models. For detailed information please refer to the challenge website and supporting API.
The L3DAS22 Challenge aims at encouraging and fostering research on machine learning for 3D audio signal processing. The challenge presents two tasks, both relying on first-order Ambisonics recordings in reverberant office environments: * Task 1: 3D Speech Enhancement. Models are expected to extract the monophonic voice signal from the 3D mixture containing various background noises. The evaluation metric is a combination of STOI and WER measures. * Task 2: 3D Sound Event Localization and Detection. Models must predict a list of the active sound events and their respective location at regular intervals of 100 milliseconds. Performance is evaluated according to localization and detection error metrics.
Each task involves 2 separate tracks: 1-mic and 2-mic recordings, respectively containing sounds acquired by one Ambisonics microphone and by an array of two Ambisonics microphones.
Baseline models
The task 1 baseline model is a beamforming U-Net) and for task 2 an augmented variant of the SELDNet architecture. The pretrained weights are also available for download here.
Task 1
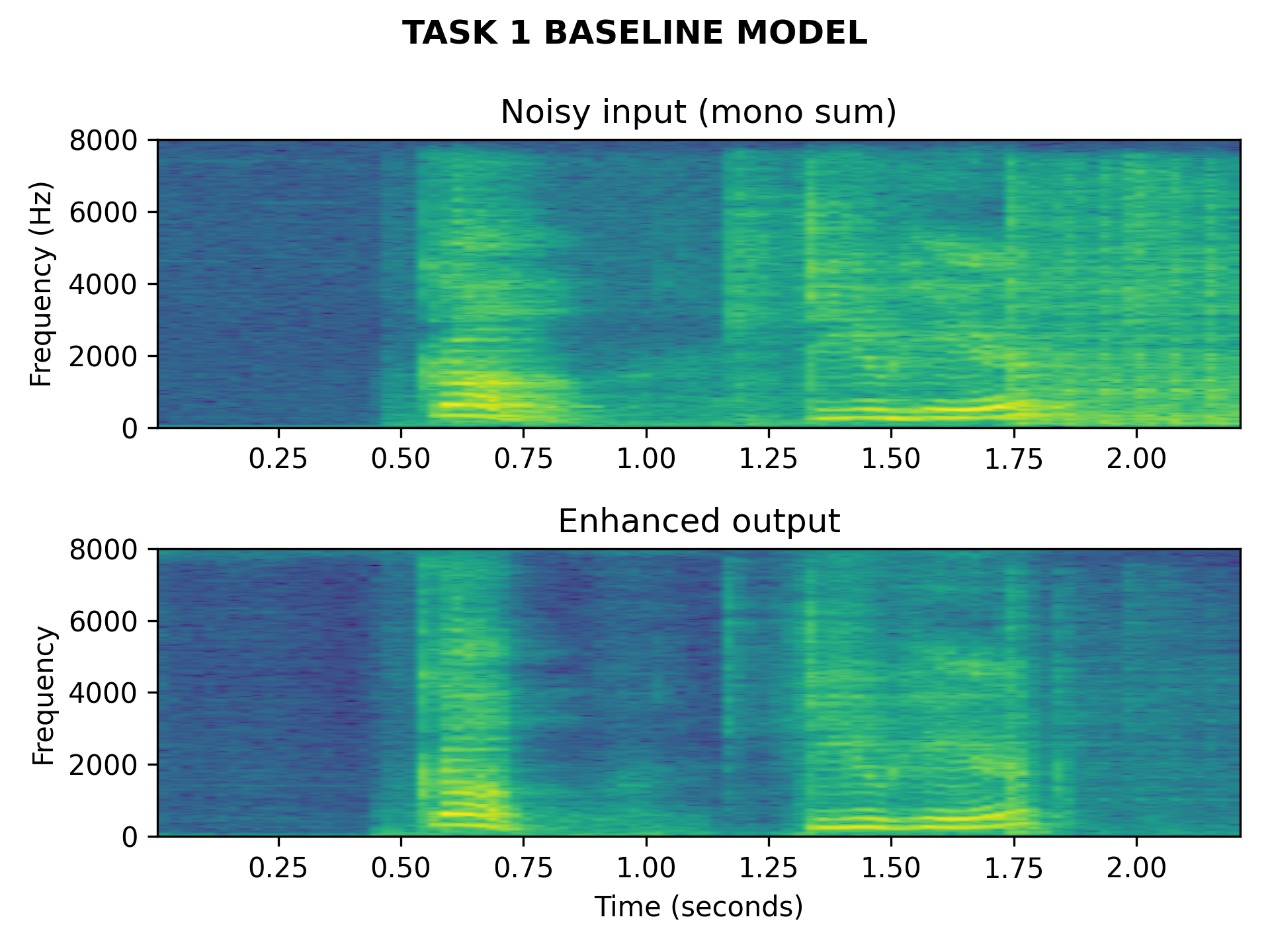
- Input: 1st order ambisonics audio mixture of speaking voice and background noises.
- Output: monoaural audio signal containing enhanced speech.
Task 2
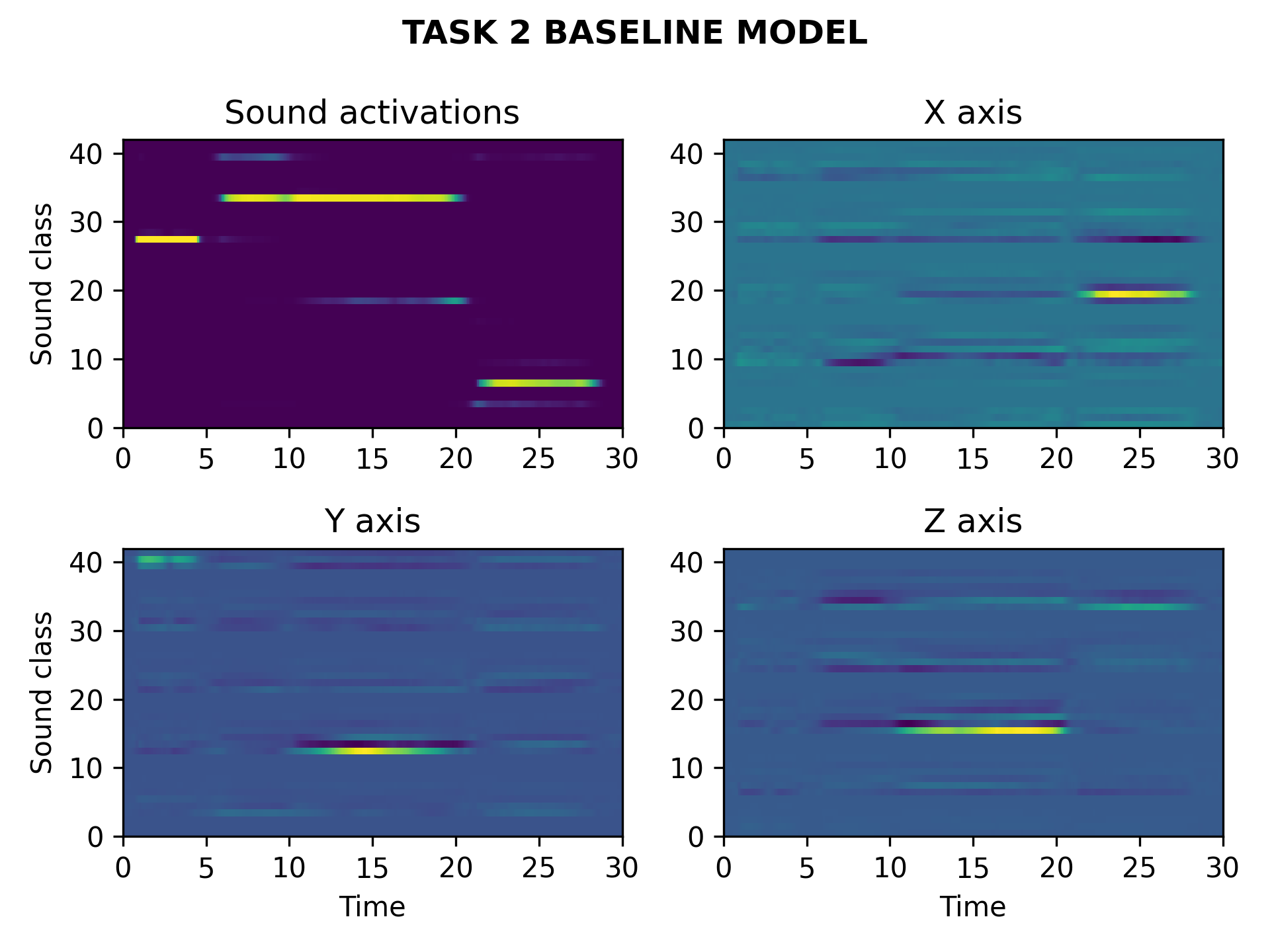
- Input: 1st order ambisonics audio mixture of various office-like sound sources.
- Output: list of active sound events and their position at regular time intervals of 100 milliseconds.
Demo usage
Whit this simple interface you can test the behavior of our pretrained baseline models. You can evaluate the models with datapoints from the L3DAS22 dataset, or with your own ambisonics sounds. Please, refer to the challenge description for details on the correct input format for each task.
UI parameters:
input: 1st order ambisonics file path (you can drag and drop a file).task: which task to evaluate (1 or 2).output_type: can be data or plot, data returns the enhanced monophonic sound for task 1 and the list of active sounds and locations for task 2, plot returns a comparision of the input and output spectrograms for task 1 and a temporal visualization of the sound events and their location for task 2.