
Readme
Pytorch Implementation of Zero-Shot Image-to-Text Generation for Visual-Semantic Arithmetic
Approach
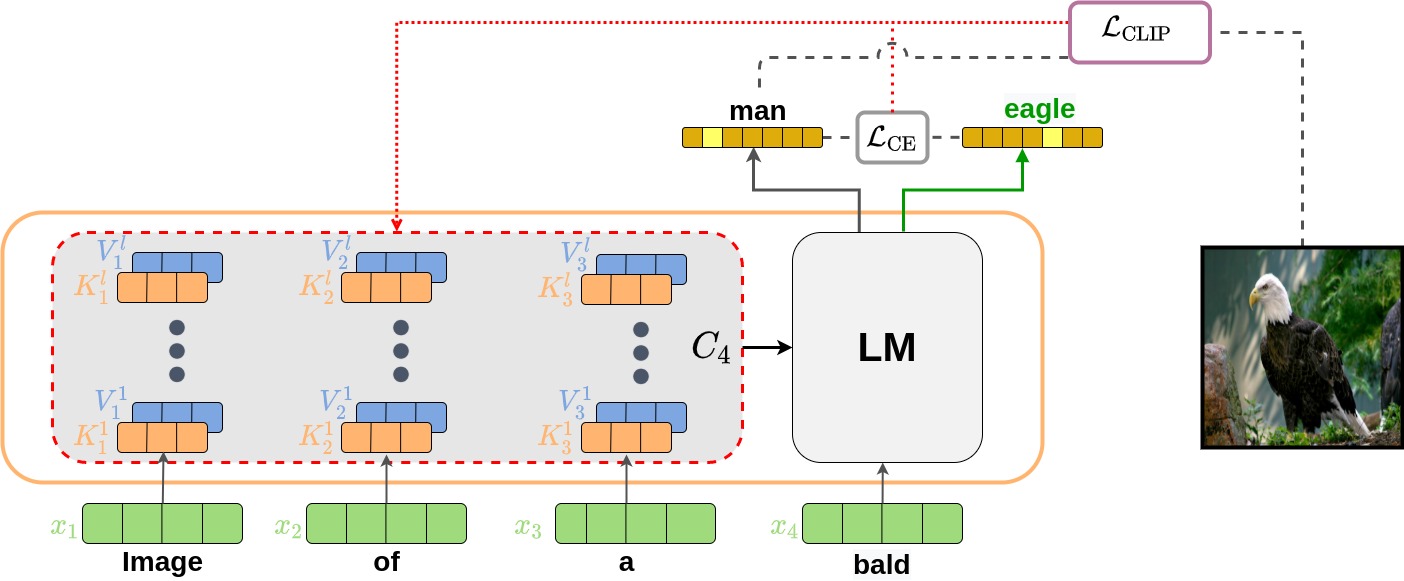
Example

Citation
Please cite our work if you use it in your research:
@article{tewel2021zero,
title={Zero-Shot Image-to-Text Generation for Visual-Semantic Arithmetic},
author={Tewel, Yoad and Shalev, Yoav and Schwartz, Idan and Wolf, Lior},
journal={arXiv preprint arXiv:2111.14447},
year={2021}
}
Model created