Readme
This is a cog implementation of https://github.com/wuqiuche/micromotion-styleGAN
Grasping the Arrow of Time from the Singularity: Decoding Micromotion in Low-dimensional Latent Spaces from StyleGAN
Project Page | Paper
Qiucheng Wu
Yifan Jiang
Junru Wu
Kai Wang
Gong Zhang
Humphrey Shi
Zhangyang Wang
Shiyu Chang
This is the official implementation of the paper “Grasping the Arrow of Time from the Singularity: Decoding Micromotion in Low-dimensional Latent Spaces from StyleGAN”.
Overview
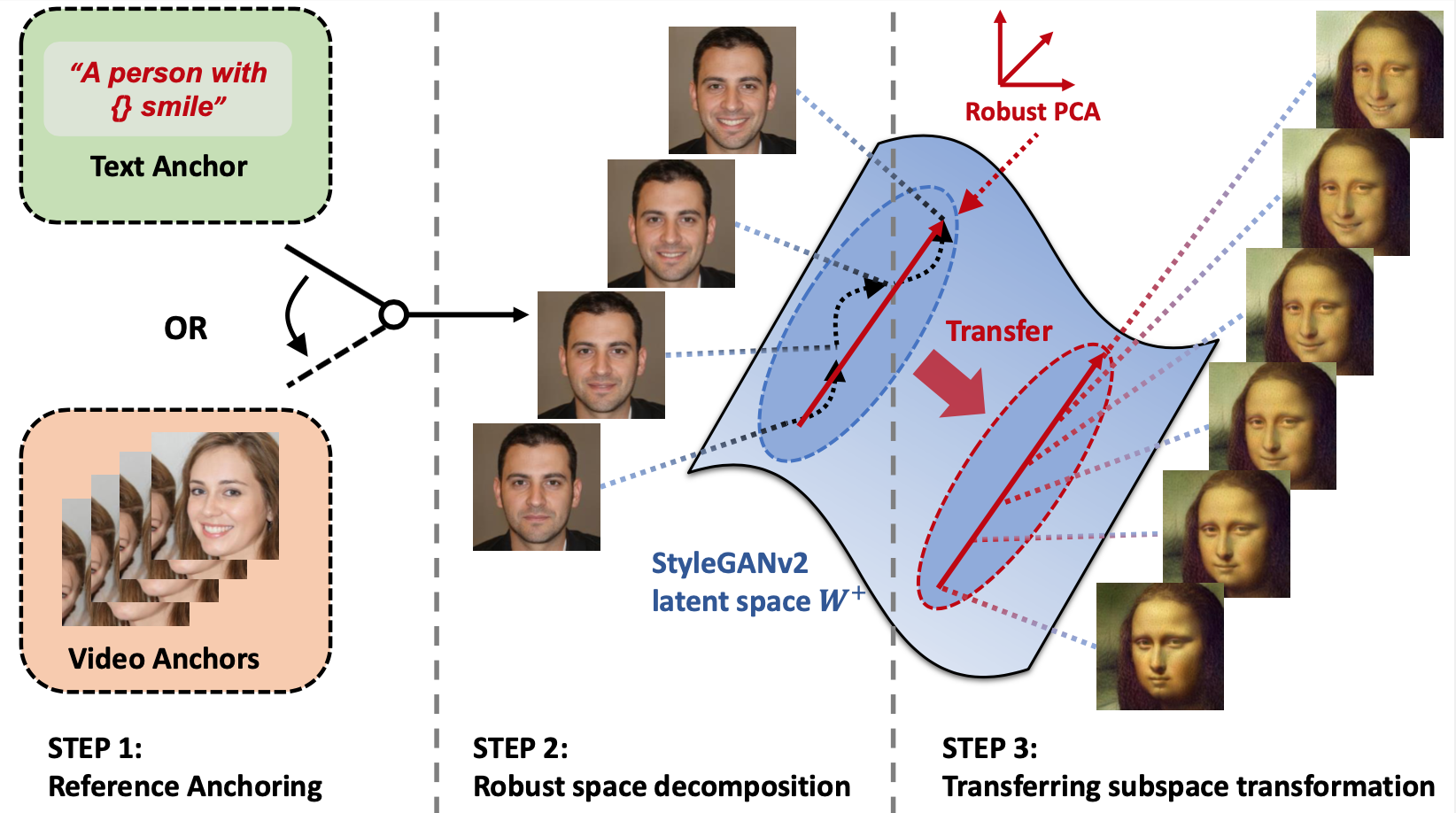
In this work, we hypothesize and demonstrate that a series of meaningful, natural, and versatile small, local movements (referred to as “micromotion”, such as expression, head movement, and aging effect) can be represented in low-rank spaces extracted from the latent space of a conventionally pre-trained StyleGAN-v2 model for face generation, with the guidance of proper “anchors” in the form of either short text or video clips. Starting from one target face image, with the editing direction decoded from the low-rank space, its micromotion features can be represented as simple as an affine transformation over its latent feature. Perhaps more surprisingly, such micromotion subspace, even learned from just single target face, can be painlessly transferred to other unseen face images, even those from vastly different domains (such as oil painting, cartoon, and sculpture faces).

The workflow
Our complete workflow can be distilled down to three simple steps: (a) collecting anchor latent codes from a single identity; (b) enforcing robustness linear decomposition to obtain a noise-free low-dimensional space; (c) applying the extracted edit direction from low-dimensional space to arbitrary input identities.