




Readme
Würstchen: Fast Diffusion for Image Generation

What is Würstchen?
Würstchen is a diffusion model, whose text-conditional component works in a highly compressed latent space of images. Why is this important? Compressing data can reduce computational costs for both training and inference by orders of magnitude. Training on 1024×1024 images is way more expensive than training on 32×32. Usually, other works make use of a relatively small compression, in the range of 4x - 8x spatial compression. Würstchen takes this to an extreme. Through its novel design, it achieves a 42x spatial compression! This had never been seen before, because common methods fail to faithfully reconstruct detailed images after 16x spatial compression. Würstchen employs a two-stage compression, what we call Stage A and Stage B. Stage A is a VQGAN, and Stage B is a Diffusion Autoencoder (more details can be found in the paper). Together Stage A and B are called the Decoder, because they decode the compressed images back into pixel space. A third model, Stage C, is learned in that highly compressed latent space. This training requires fractions of the compute used for current top-performing models, while also allowing cheaper and faster inference. We refer to Stage C as the Prior.

Why another text-to-image model?
Well, this one is pretty fast and efficient. Würstchen’s biggest benefits come from the fact that it can generate images much faster than models like Stable Diffusion XL, while using a lot less memory! So for all of us who don’t have A100s lying around, this will come in handy. Here is a comparison with SDXL over different batch sizes:
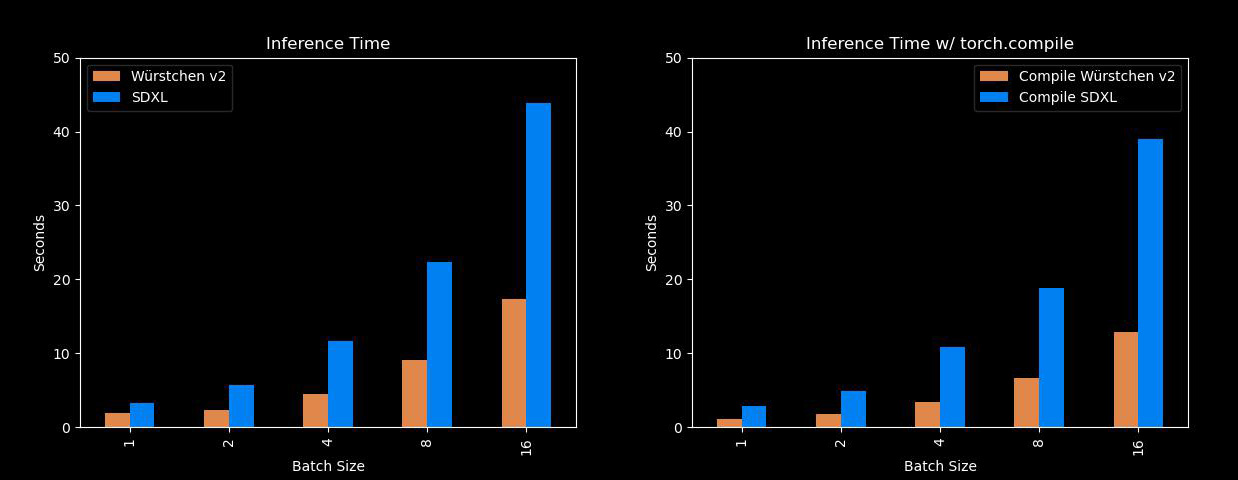
In addition to that, another greatly significant benefit of Würstchen comes with the reduced training costs. Würstchen v1, which works at 512x512, required only 9,000 GPU hours of training. Comparing this to the 150,000 GPU hours spent on Stable Diffusion 1.4 suggests that this 16x reduction in cost not only benefits researchers when conducting new experiments, but it also opens the door for more organizations to train such models. Würstchen v2 used 24,602 GPU hours. With resolutions going up to 1536, this is still 6x cheaper than SD1.4, which was only trained at 512x512.
What image sizes does Würstchen work on?
Würstchen was trained on image resolutions between 1024x1024 & 1536x1536. We sometimes also observe good outputs at resolutions like 1024x2048. Feel free to try it out.
We also observed that the Prior (Stage C) adapts extremely fast to new resolutions. So finetuning it at 2048x2048 should be computationally cheap.
