Object detection and segmentation
These models distinguish objects in images and videos. You can use them to detect which things are in a scene, what they are and where they're located. You can also cut objects out from the scene, or create masks for inpainting and other tasks.
Best for detecting objects in images: adirik/grounding-dino
To find specific things in an image, we recommend adirik/grounding-dino. You can input any number of text labels and get back bounding boxes for each of the objects you're looking for. It's cheap and takes less than a second to run.
Best for detecting objects in videos: zsxkib/yolo-world
Use this model to find and track things in videos from text labels. You'll get back bounding boxes for each object by frame.
You can also use zsxkib/yolo-world for images. It's similar in performance to the above, but sometimes one or the other will work better for a given use case.
Best for segmentation: meta/sam-2 and meta/sam-2-video
Meta's Segment Anything Model is a great way to extract things from images and videos, or to create masks for inpainting. They require a little more preparation than the bounding box models: you'll need to send the coordinates of click points for the objects you want to segment.
If you want to segment objects with text labels, try schananas/grounded_sam. Send a text prompt with object names and you'll get back a mask for the collection of objects you've described.
Best for tracking objects in videos: zsxkib/samurai
Input a video and the coordinates for an object, and this specialized version of SAM will track the object across frames.
Best for labeling whole scenes: cjwbw/semantic-segment-anything
This model will label every pixel in an image with a class. It's great for creating training data and creating masks for inpainting.
Featured models

 zsxkib/samurai
zsxkib/samuraiSAMURAI: Adapting Segment Anything Model for Zero-Shot Visual Tracking with Motion-Aware Memory
Updated 1 year, 7 months ago
545 runs

 meta/sam-2-video
meta/sam-2-videoSAM 2: Segment Anything v2 (for videos)
Updated 1 year, 11 months ago
81.4K runs
 meta/sam-2
meta/sam-2SAM 2: Segment Anything v2 (for Images)
Updated 1 year, 11 months ago
197.2K runs
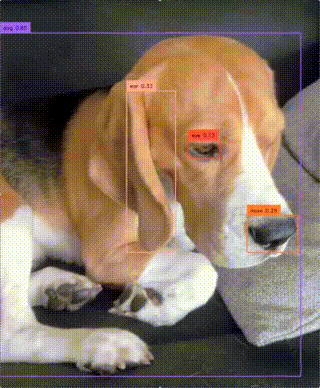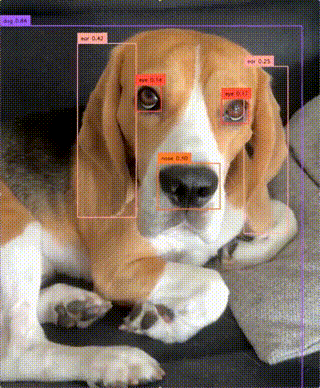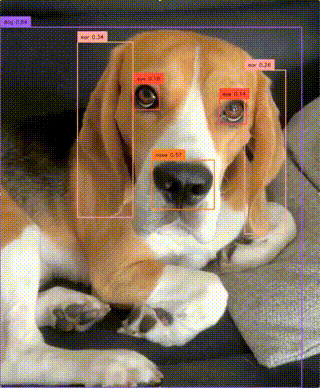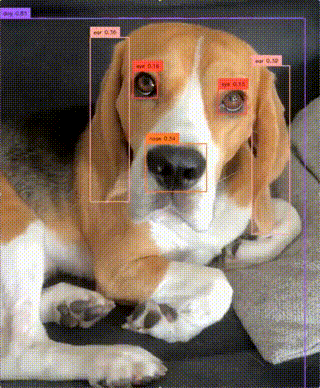 zsxkib/yolo-world
zsxkib/yolo-worldReal-Time Open-Vocabulary Object Detection
Updated 2 years, 5 months ago
14.2K runs

 schananas/grounded_sam
schananas/grounded_samMask prompting based on Grounding DINO & Segment Anything | Integral cog of doiwear.it
Updated 2 years, 8 months ago
2.7M runs

 adirik/grounding-dino
adirik/grounding-dinoDetect everything with language!
Updated 2 years, 8 months ago
39.3M runs

 cjwbw/semantic-segment-anything
cjwbw/semantic-segment-anythingAdding semantic labels for segment anything
Updated 3 years, 3 months ago
37.8K runs
Recommended Models
Frequently asked questions
Which models are the fastest for object detection?
If you need low-latency detection, adirik/grounding-dino is one of the fastest models in the object detection & segmentation collection. It’s designed for quick, open-vocabulary detection — you can pass in text labels like “dog,” “bicycle,” or “traffic light,” and it returns bounding boxes in roughly a second for most images.
Fast models work well for simple scenes, but they may be less precise in crowded or complex images.
Which models offer the best balance of accuracy and flexibility?
For advanced use cases that require more control or detail, meta/sam-2 (for images) and zsxkib/yolo-world (for videos) are strong choices.
- SAM-2 gives you precise segmentation masks, which are great for tasks like editing or inpainting.
- YOLO-World combines solid speed with flexible object tracking across frames.
These models strike a good balance between versatility and performance.
What works best for detecting specific objects in images with text prompts?
When your task is to detect particular objects from text labels — for example, “find the person and the umbrella” — adirik/grounding-dino is built exactly for that. It uses open-vocabulary detection, meaning you can describe any object with text, not just a fixed list of categories.
It’s particularly good for images with clear subjects and minimal occlusion.
What should I use for tracking or detecting objects in video clips?
If you need to follow objects over time — such as people, vehicles, or sports equipment — zsxkib/yolo-world or zsxkib/samurai are well suited.
These models provide object detection and tracking across multiple frames, maintaining consistent IDs or masks as objects move.
How do the main types of object detection and segmentation models differ?
- Bounding-box detection (e.g., adirik/grounding-dino): Finds and labels objects with simple boxes around them.
- Segmentation/mask models (e.g., meta/sam-2): Return pixel-precise masks for selected regions, which is ideal for cutouts or fine-grained editing.
- Tracking models (e.g., zsxkib/yolo-world, zsxkib/samurai): Detect and follow objects across video frames.
- Speed vs detail: Faster models are ideal for quick detections or lightweight workflows, while mask or tracking models provide more precision but require more compute and sometimes extra inputs.
What kinds of outputs can I expect?
Depending on the model, you may get:
- A list of detected objects with bounding boxes.
- Segmentation masks for selected regions.
- Tracked bounding boxes or masks across multiple video frames.
Some segmentation models, like meta/sam-2, may require you to provide click points or coordinates to specify which regions to segment.
How can I self-host or publish my own object detection model?
You can package your own model (for example, a fine-tuned version of YOLO or SAM) with Cog and push it to Replicate. This allows you to define your own input structure, such as image or video plus text prompts, and control how it’s shared and used.
Can I use object detection and segmentation models for commercial work?
Many models in the object detection & segmentation collection allow commercial use, but license terms vary. Check each model’s license page for attribution or usage restrictions before deploying in production or commercial environments.
How do I use these models on Replicate?
- Pick a model from the object detection & segmentation collection.
- Upload your image or video, or provide a URL.
- Add any text labels or click points if the model requires them.
- Run the model to get detections, masks, or tracks.
- Download the output for annotation, editing, analysis, or downstream tasks.
What should I keep in mind when working with detection and segmentation models?
- Clear, well-lit inputs improve accuracy.
- adirik/grounding-dino works best with unambiguous text labels.
- meta/sam-2 often needs prompt points to get the best mask output.
- Larger or more complex images may take longer to process.
- Tracking performance depends on stable frame quality and object visibility.
- Test with a few examples before scaling up to larger workloads.






















