Embedding models
These models generate vector representations that capture the semantics of text, images, and more. Embeddings power search, recommendations, and clustering.
Our pick for text: Multilingual E5
For most text applications, we recommend beautyyuyanli/multilingual-e5-large. It's fast, cheap and produces high-quality embeddings suitable for semantic search, topic modeling, and classification.
Our pick for images: CLIP
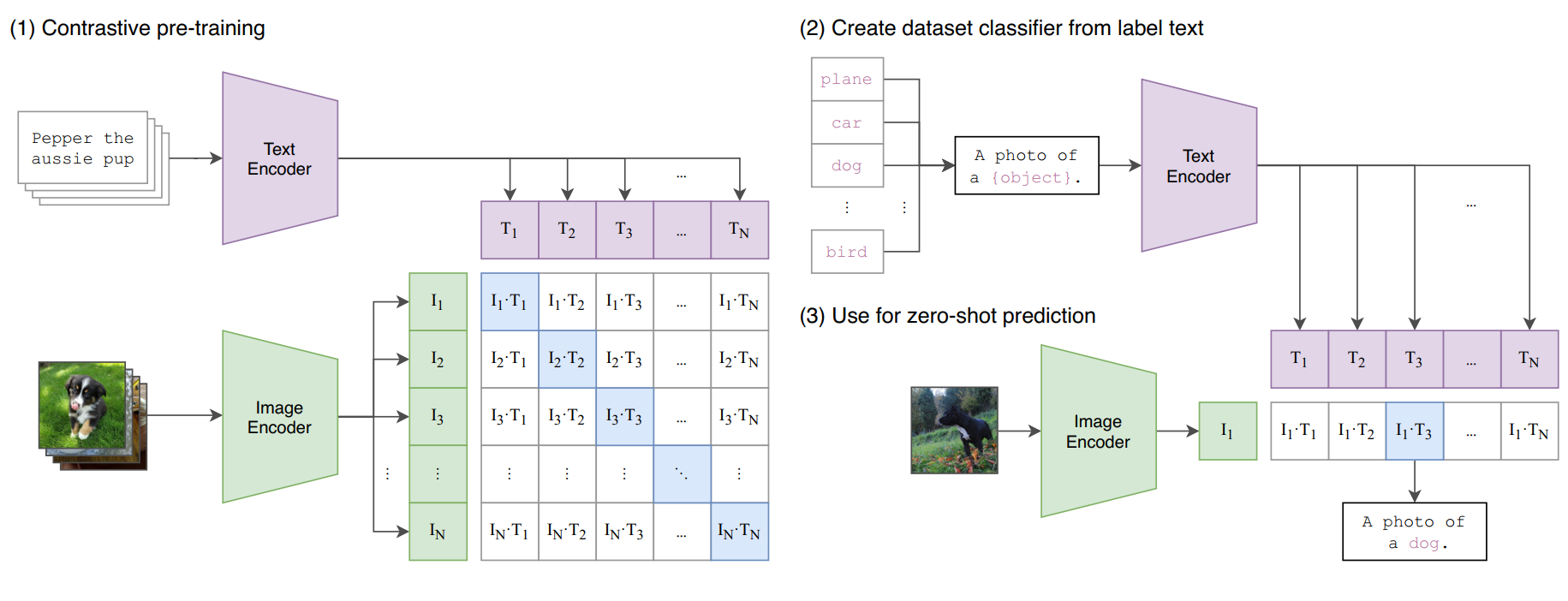
CLIP is the go-to model for image similarity search and clustering. Incredibly popular and cost-effective, CLIP embeddings capture the semantic content of images, making it easy to find similar ones. Just pass in an image URL or a text string and you're good to go.
Best for multimodal: ImageBind
To jointly embed text, images, and audio, ImageBind is in a class of its own. While more expensive than unimodal models, its ability to unify different data types enables unique applications like searching images with text queries or finding relevant audio clips. If you're working on multimodal search or retrieval, ImageBind is worth the investment.
Featured models

 beautyyuyanli/multilingual-e5-large
beautyyuyanli/multilingual-e5-largemultilingual-e5-large: A multi-language text embedding model
Updated 2 years, 6 months ago
75.3M runs
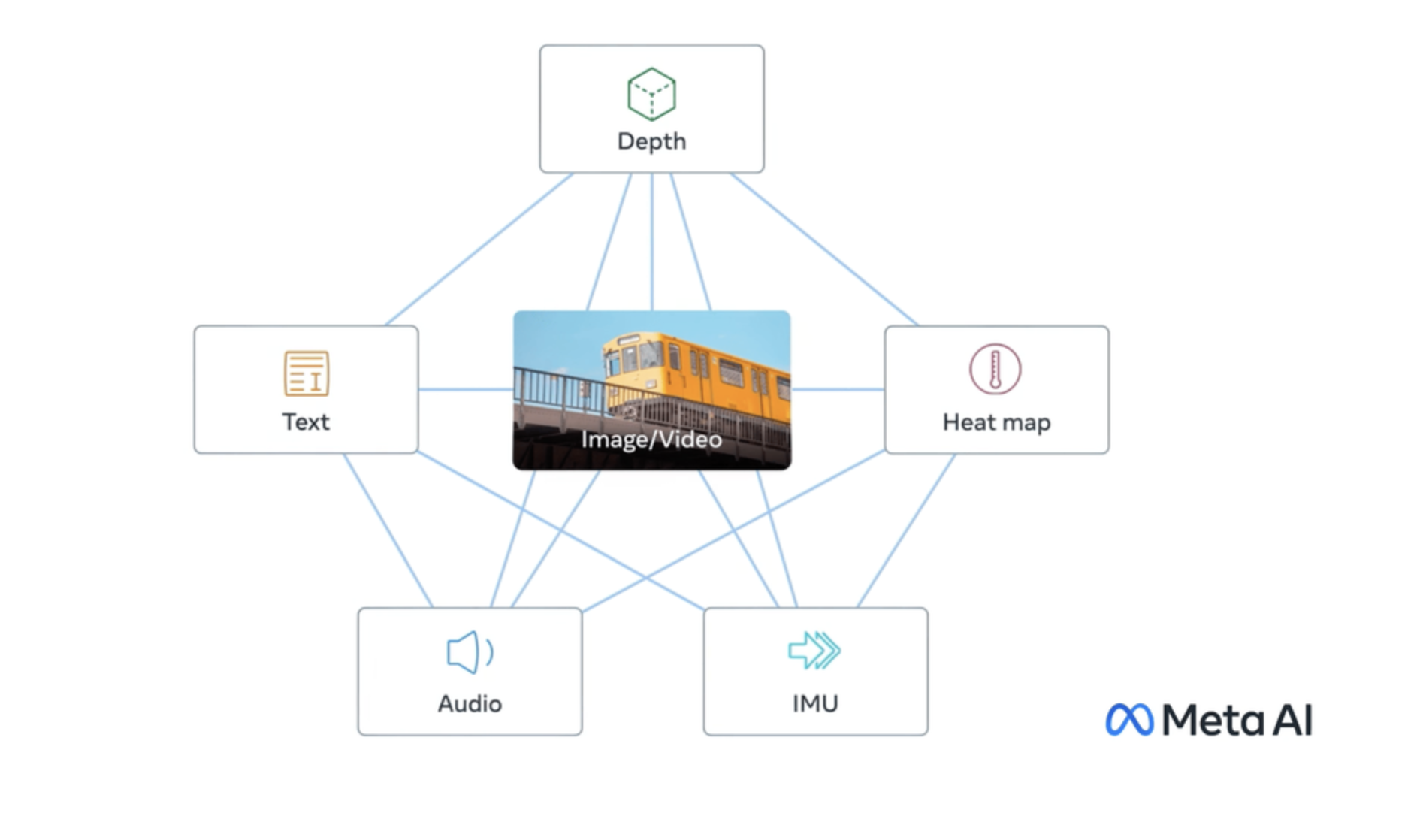
 daanelson/imagebind
daanelson/imagebindA model for text, audio, and image embeddings in one space
Updated 3 years, 2 months ago
9.5M runs

 andreasjansson/clip-features
andreasjansson/clip-featuresReturn CLIP features for the clip-vit-large-patch14 model
Updated 3 years, 4 months ago
165.3M runs
Recommended Models
Frequently asked questions
Which models are the fastest?
If you need quick results for text embeddings, beautyyuyanli/multilingual-e5-large and replicate/all-mpnet-base-v2 are both optimized for speed and work well for search and clustering tasks.
For image or multimodal data, andreasjansson/clip-features and krthr/clip-embeddings provide fast inference times without sacrificing much accuracy.
Which models offer the best balance of cost and quality?
beautyyuyanli/multilingual-e5-large offers excellent performance for text embeddings in multiple languages while remaining efficient to run.
For images, andreasjansson/clip-features hits the sweet spot—it’s reliable, cost-effective, and widely used in production for similarity search.
If you need multimodal flexibility, daanelson/imagebind provides strong results across text, image, and audio at a higher compute cost.
What works best for text embeddings?
beautyyuyanli/multilingual-e5-large is the top choice for text-based search, classification, and clustering.
It performs well across languages, making it suitable for multilingual apps, chat search, or semantic retrieval.
Other options like ibm-granite/granite-embedding-278m-multilingual and lucataco/snowflake-arctic-embed-l are great alternatives for large-scale enterprise or research use.
What works best for image or visual embeddings?
For image-only tasks, andreasjansson/clip-features and krthr/clip-embeddings are the most dependable.
They’re based on CLIP’s ViT-L/14 architecture and produce embeddings that capture both visual detail and semantic meaning—ideal for image similarity, clustering, and cross-modal search.
What works best for multimodal embeddings?
daanelson/imagebind excels at embedding text, images, and audio in the same space. This makes it perfect for applications like searching for sounds using text prompts or finding images that match an audio clip.
For multilingual or multimodal-heavy datasets, zsxkib/jina-clip-v2 is another strong choice with 89-language support and high-resolution inputs.
What’s the difference between text, image, and multimodal embeddings?
- Text embeddings convert written text into vectors that represent meaning, useful for semantic search or classification.
- Image embeddings represent visual content and are great for similarity or clustering tasks.
- Multimodal embeddings unify several input types—text, image, audio—into one shared vector space, enabling cross-media retrieval or comparison.
What kinds of outputs can I expect from these models?
All embedding models output numeric vectors, usually arrays of floats.
These vectors can be stored in a database or used directly for semantic search, recommendation systems, clustering, or retrieval-augmented generation (RAG).
How can I self-host or push a model to Replicate?
Many embedding models, like replicate/all-mpnet-base-v2 or beautyyuyanli/multilingual-e5-large, can be self-hosted using Cog or Docker.
To publish your own embedding model, create a replicate.yaml defining the input and output schema, push it to your account, and Replicate handles deployment.
Can I use these models for commercial work?
Yes, most embedding models are licensed for commercial use. That includes E5, CLIP, and ImageBind, though you should always double-check the License tab on each model’s page for any restrictions.
How do I use or run these models?
Provide text, image URLs, or audio inputs depending on the model type.
For example:
- “Generate embeddings for this paragraph” → beautyyuyanli/multilingual-e5-large
- “Find similar product photos” → andreasjansson/clip-features
- “Match sounds to visuals” → daanelson/imagebind
The output will be a numerical vector you can use for similarity or clustering.
What should I know before running a job in this collection?
- Choose the embedding type (text, image, or multimodal) that fits your data.
- Keep embeddings consistent—don’t mix model outputs when comparing similarity scores.
- Dimensionality varies by model, so make sure your database or vector store supports it.
- Preprocessing (like lowercasing or trimming text) can improve embedding consistency.
Any other collection-specific tips or considerations?
- For multilingual search, stick with beautyyuyanli/multilingual-e5-large or ibm-granite/granite-embedding-278m-multilingual.
- For hybrid text+image systems, pair andreasjansson/clip-features or zsxkib/jina-clip-v2 with a text retriever.
- Store normalized embeddings (unit vectors) for better cosine similarity performance.
- When testing models, visualize your embeddings using tools like t-SNE or UMAP to inspect clustering behavior.