

Readme
HRDA: Context-Aware High-Resolution Domain-Adaptive Semantic Segmentation
by Lukas Hoyer, Dengxin Dai, and Luc Van Gool
Overview
Unsupervised domain adaptation (UDA) aims to adapt a model trained on synthetic data to real-world data without requiring expensive annotations of real-world images. As UDA methods for semantic segmentation are usually GPU memory intensive, most previous methods operate only on downscaled images. We question this design as low-resolution predictions often fail to preserve fine details. The alternative of training with random crops of high-resolution images alleviates this problem but falls short in capturing long-range, domain-robust context information.
Therefore, we propose HRDA, a multi-resolution training approach for UDA, that combines the strengths of small high-resolution crops to preserve fine segmentation details and large low-resolution crops to capture long-range context dependencies with a learned scale attention, while maintaining a manageable GPU memory footprint.

HRDA enables adapting small objects and preserving fine segmentation details. It significantly improves the state-of-the-art performance by 5.5 mIoU for GTA→Cityscapes and by 4.9 mIoU for Synthia→Cityscapes, resulting in an unprecedented performance of 73.8 and 65.8 mIoU, respectively.

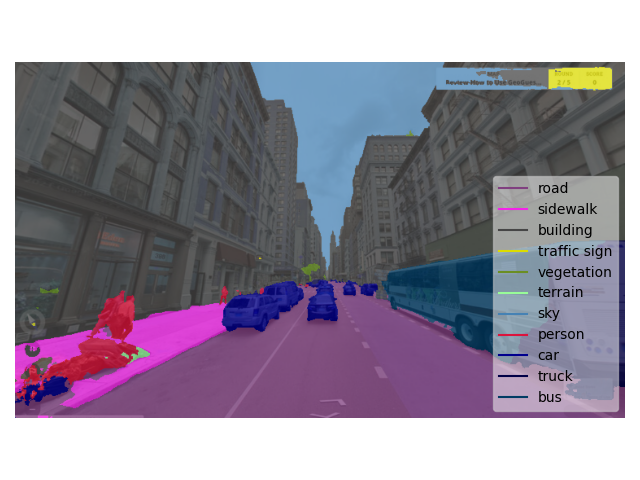
The more detailed domain-adaptive semantic segmentation of HRDA, compared to the previous state-of-the-art UDA method DAFormer, can also be observed in example predictions from the Cityscapes validation set.


For more information on HRDA, please check our [Paper].
If you find HRDA useful in your research, please consider citing:
@Article{hoyer2022hrda,
title={{HRDA}: Context-Aware High-Resolution Domain-Adaptive Semantic Segmentation},
author={Hoyer, Lukas and Dai, Dengxin and Van Gool, Luc},
journal={arXiv preprint arXiv:2204.13132},
year={2022}
}