Mamba 2.8B state space language model fine tuned for chat
Lightweight multimodal model for visual question answering, reasoning and captioning
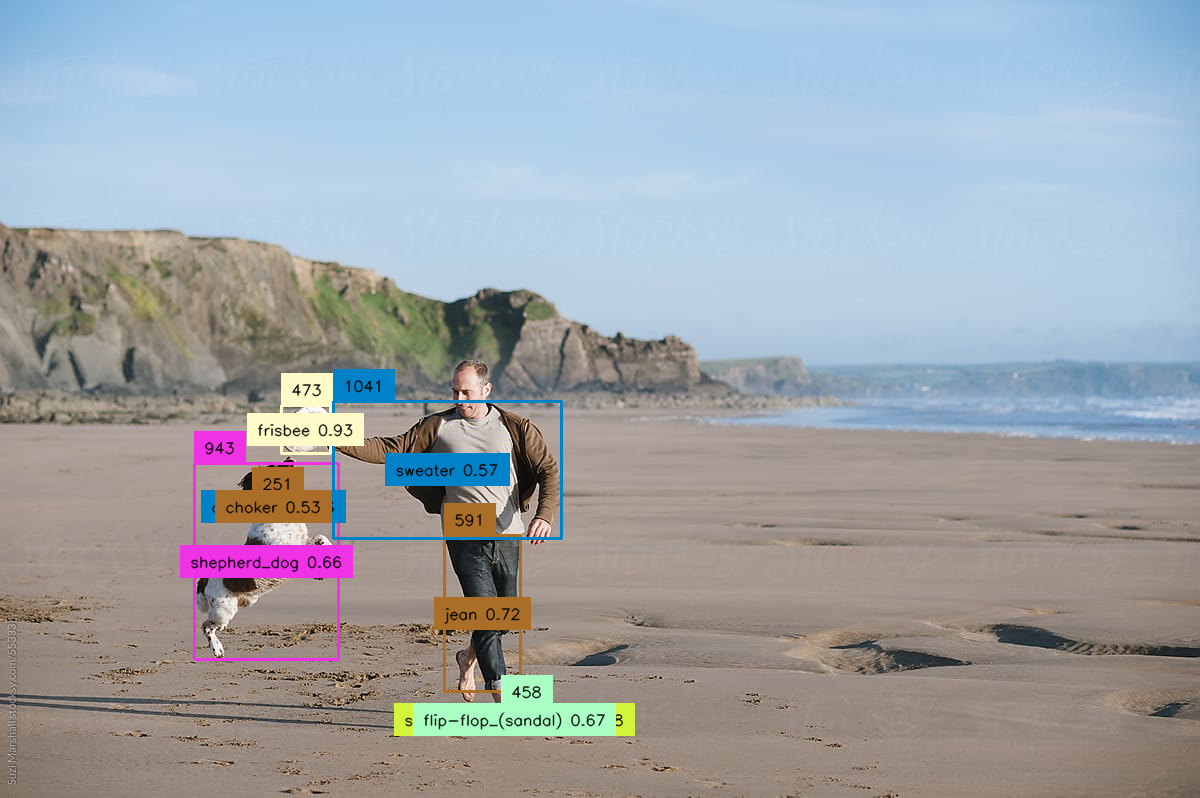
Detects objects in an image
Generate videos from text prompts with Kandinsky-2.2
E5-mistral-7b-instruct language embedding model
Flux lora, use "CNSTLL" to trigger
Flux lora, use "in the style of FNTSYRCH" to trigger
Fast text-to-3D Gaussian generation by bridging 2D and 3D diffusion models
Detect everything with language!
Zero-shot speech synthesizer for text-to-speech and voice conversion
Image-Prompt Multi-view Diffusion for 3D Generation
Inst-Inpaint: Instructing to Remove Objects with Diffusion Models
Realistic interior design with text and image inputs
Kosmos-G: Generating Images in Context with Multimodal Large Language Models
LEdits++ for image editing
PyTorch version of Lightweight OpenPose as introduced in "Real-time 2D Multi-Person Pose Estimation on CPU: Lightweight OpenPose"
Generating object-level shape variations with Stable Diffusion
Base version of Mamba 130M, a 130 million parameter state space language model
Base version of Mamba 1.4B, a 1.4 billion parameter state space language model
Base version of Mamba 2.8B, a 2.8 billion parameter state space language model
Base version of Mamba 2.8B Slim Pyjama, a 2.8 billion parameter state space language model
This model is cold. You'll get a fast response if the model is warm and already running, and a slower response if the model is cold and starting up.