





Readme
This is a cog implementation of https://github.com/microsoft/VQ-Diffusion
VQ-Diffusion (CVPR2022, Oral) and
Improved VQ-Diffusion
Overview
This is the official repo for the paper: Vector Quantized Diffusion Model for Text-to-Image Synthesis and Improved Vector Quantized Diffusion Models.
The code is the same as https://github.com/cientgu/VQ-Diffusion, some issues that have been raised can refer to it.
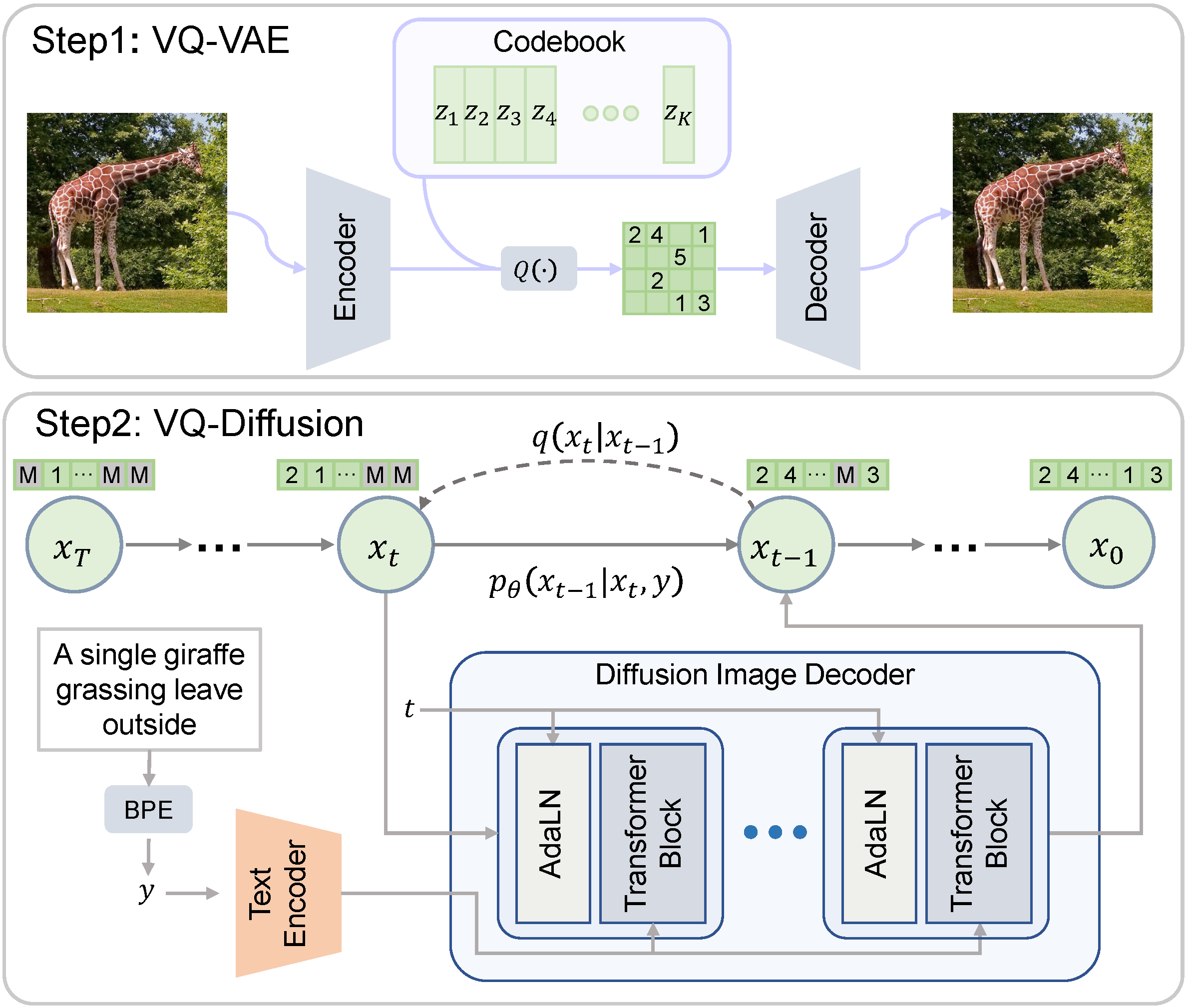
VQ-Diffusion is based on a VQ-VAE whose latent space is modeled by a conditional variant of the recently developed Denoising Diffusion Probabilistic Model (DDPM). It produces significantly better text-to-image generation results when compared with Autoregressive models with similar numbers of parameters. Compared with previous GAN-based methods, VQ-Diffusion can handle more complex scenes and improve the synthesized image quality by a large margin.
Framework
Cite VQ-Diffusion
if you find our code helpful for your research, please consider citing:
@article{gu2021vector,
title={Vector Quantized Diffusion Model for Text-to-Image Synthesis},
author={Gu, Shuyang and Chen, Dong and Bao, Jianmin and Wen, Fang and Zhang, Bo and Chen, Dongdong and Yuan, Lu and Guo, Baining},
journal={arXiv preprint arXiv:2111.14822},
year={2021}
}
Acknowledgement
Thanks to everyone who makes their code and models available. In particular,
License
This project is licensed under the license found in the LICENSE file in the root directory of this source tree.
Microsoft Open Source Code of Conduct
Contact Information
For help or issues using VQ-Diffusion, please submit a GitHub issue. For other communications related to VQ-Diffusion, please contact Shuyang Gu (gsy777@mail.ustc.edu.cn) or Dong Chen (doch@microsoft.com).