🕹️FramePack: video diffusion that feels like image diffusion🎥
A "Hello World" model for me to get to grips with `cog` and Replicate
Transform your text into a beautiful two-tone color gradient that represents your emotions.
Age prediction using CLIP - Patched version of `https://replicate.com/andreasjansson/clip-age-predictor` that works with the new version of cog!
Logit Warping via Biases for Google's FLAN-T5-small
🐲 DragGAN 🐉 - "Drag Your GAN: Interactive Point-based Manipulation on the Generative Image Manifold"
📽️ Increase Framerate 🎬 ST-MFNet: A Spatio-Temporal Multi-Flow Network for Frame Interpolation
🎨 AnimateDiff (w/ MotionLoRAs for Panning, Zooming, etc): Animate Your Personalized Text-to-Image Diffusion Models without Specific Tuning
✨DiffBIR: Towards Blind Image Restoration with Generative Diffusion Prior
🎨AnimateDiff Prompt Travel🧭 Seamlessly Navigate and Animate Between Text-to-Image Prompts for Dynamic Visual Narratives
Monster Labs' Controlnet QR Code Monster v2 For SD-1.5 on top of AnimateDiff Prompt Travel (Motion Module SD 1.5 v2)
FILM: Frame Interpolation for Large Motion, In ECCV 2022.
Identifies NSFW images
Create song covers with any RVC v2 trained AI voice from audio files.
Create your own Realistic Voice Cloning (RVC v2) dataset using a YouTube link
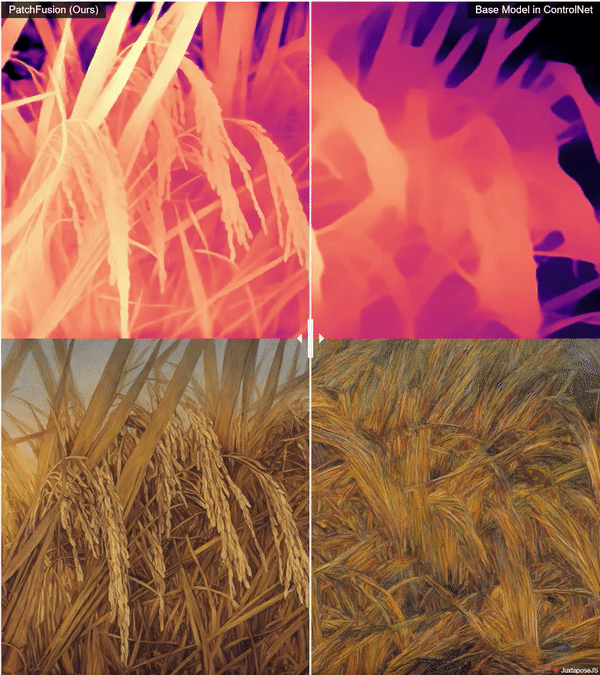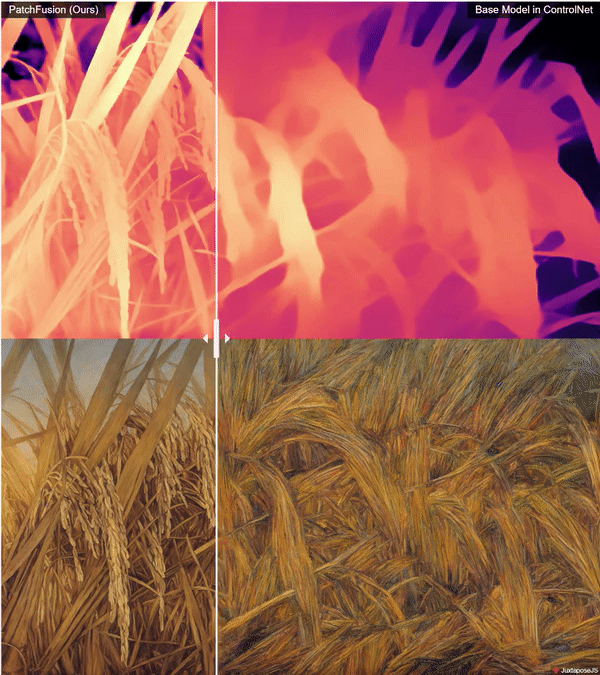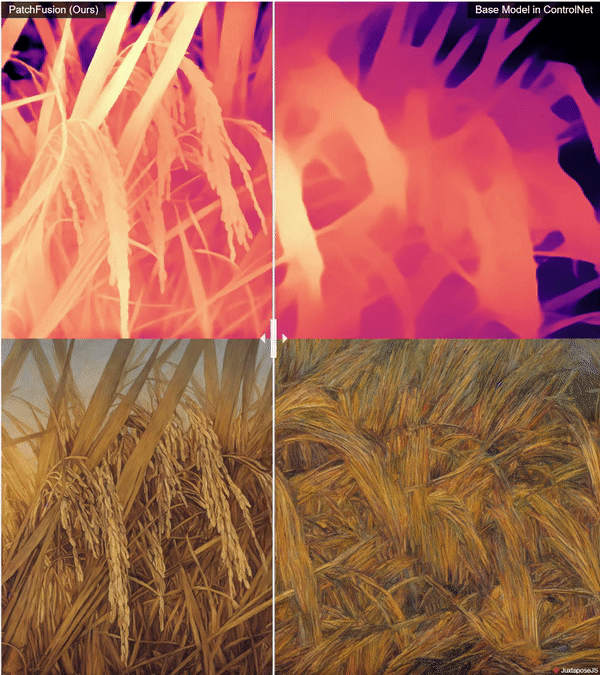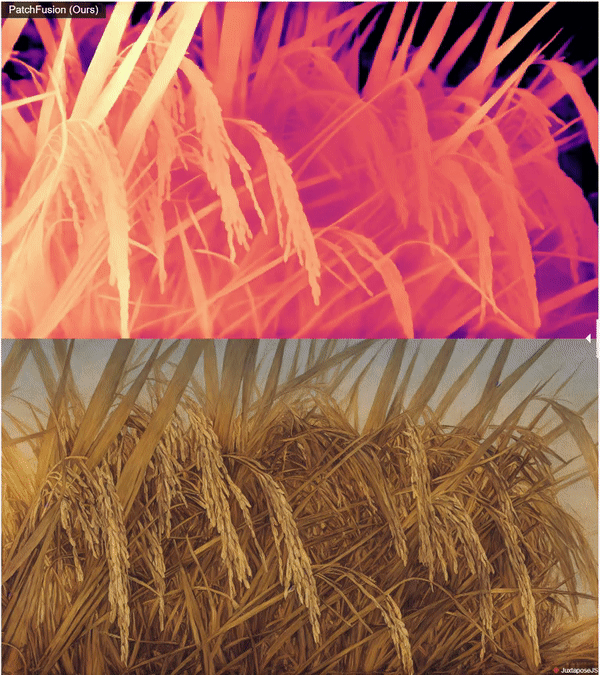
Super High Quality Depth Maps 🗺️: An End-to-End Tile-Based Framework 🏗️ for High-Resolution Monocular Metric Depth Estimation 🔍📏
Unofficial Re-Trained AnimateAnyone (Image + DWPose Video → Animated Video of Image)
Make realistic images of real people instantly
🖼️ Super fast 1.5B Image Captioning/VQA Multimodal LLM (Image-to-Text) 🖋️
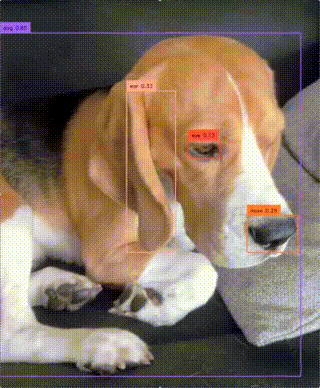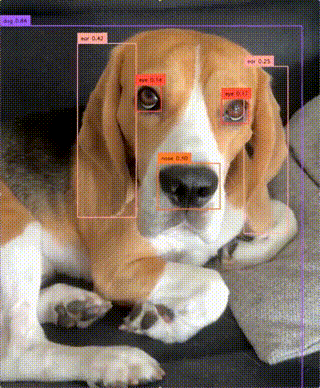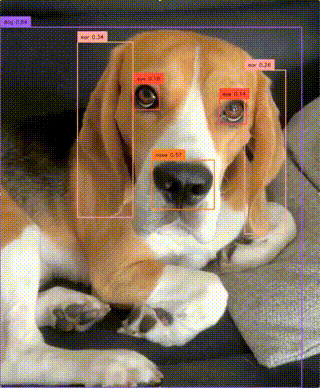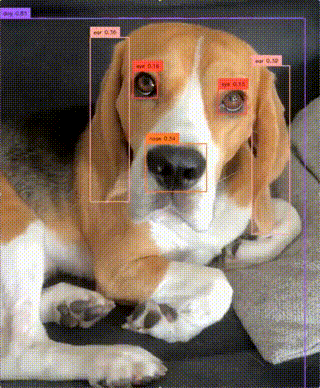
Real-Time Open-Vocabulary Object Detection
🗣️ TalkNet-ASD: Detect who is speaking in a video
This model is not yet booted but ready for API calls. Your first API call will boot the model and may take longer, but after that subsequent responses will be fast.
This model runs on A100 (80GB).