
Controlling Vision-Language Models for Universal Image Restoration
Notice!!
🙁 In testing we found that the current pretrained model is still difficult to process some real-world images which might have distribution shifts with our training dataset (captured from different devices or with different resolutions or degradations). We regard it as a future work and will try to make our model more practical! We also encourage users who are interested in our work to train their own models with larger dataset and more degradation types.
🙁 BTW, we also found that directly resizing input images will lead a poor performance for most tasks. We could try to add the resize step into the training but it always destroys the image quality due to interpolation.
🙁 For the inpainting task our current model only supports face inpainting due to the dataset limitation. We provide our mask examples and you can use the generate_masked_face script to generate uncompleted faces.
Overview framework:
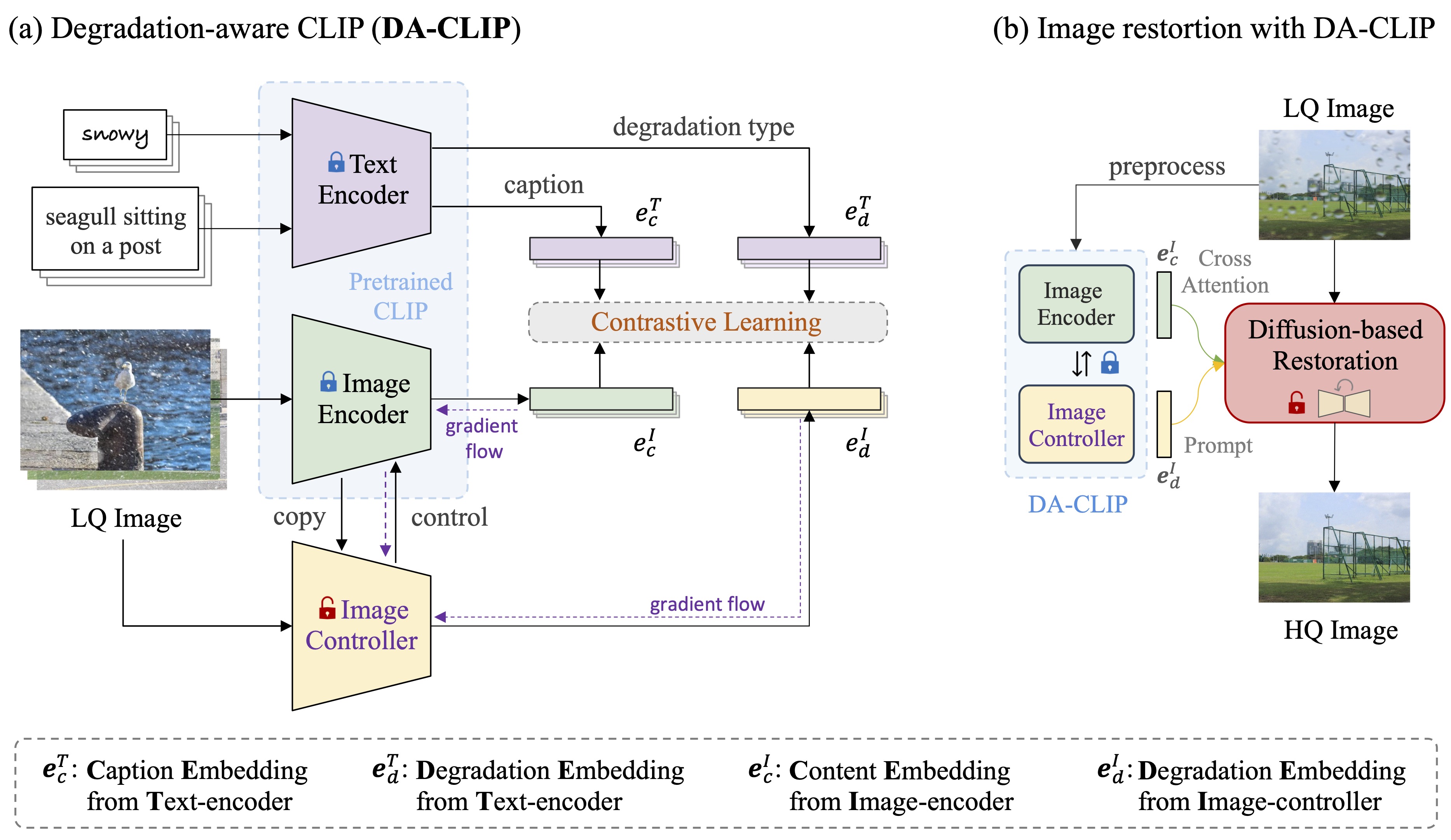
Acknowledgment: Our DA-CLIP is based on IR-SDE and open_clip. Thanks for their code!
Contact
If you have any question, please contact: ziwei.luo@it.uu.se
Citations
If our code helps your research or work, please consider citing our paper. The following are BibTeX references:
@article{luo2023controlling,
title={Controlling Vision-Language Models for Universal Image Restoration},
author={Luo, Ziwei and Gustafsson, Fredrik K and Zhao, Zheng and Sj{\"o}lund, Jens and Sch{\"o}n, Thomas B},
journal={arXiv preprint arXiv:2310.01018},
year={2023}
}