
Readme
Demucs Music Source Separation
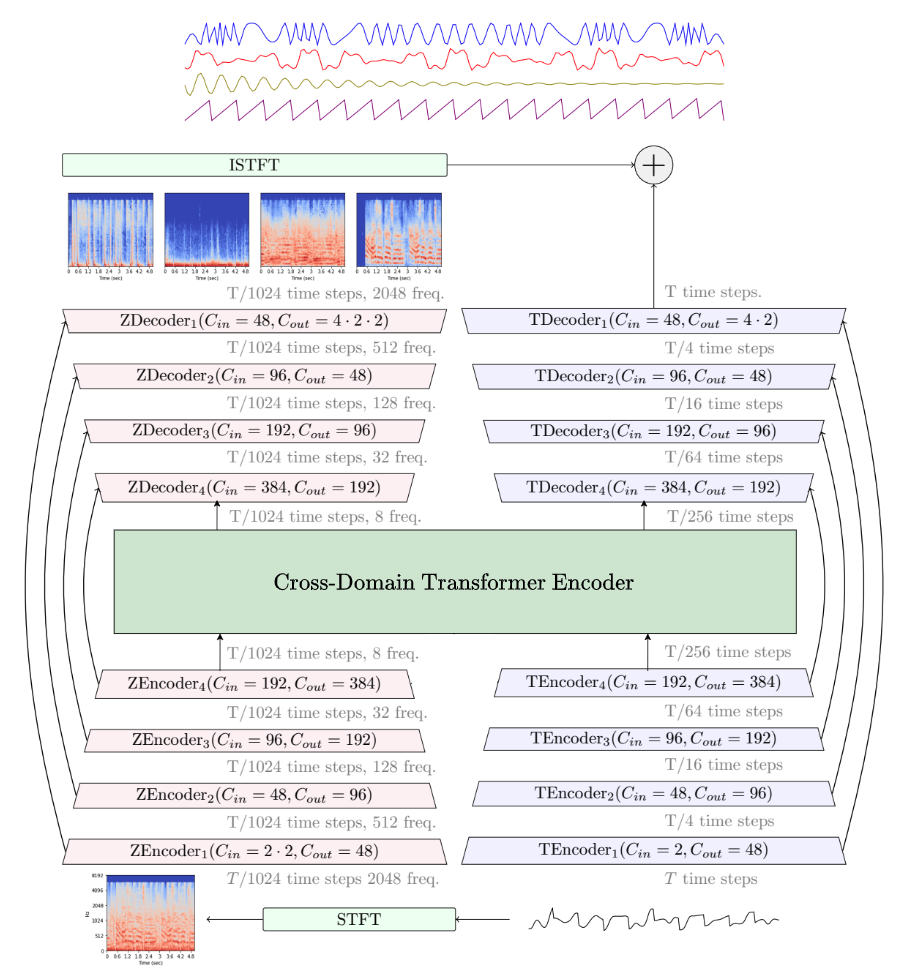
Demucs is a state-of-the-art music source separation model, currently capable of separating drums, bass, and vocals from the rest of the accompaniment. Demucs is based on a U-Net convolutional architecture inspired by [Wave-U-Net][waveunet]. The v4 version features [Hybrid Transformer Demucs][htdemucs], a hybrid spectrogram/waveform separation model using Transformers. It is based on [Hybrid Demucs][hybrid_paper] (also provided in this repo) with the innermost layers are replaced by a cross-domain Transformer Encoder. This Transformer uses self-attention within each domain, and cross-attention across domains. The model achieves a SDR of 9.00 dB on the MUSDB HQ test set. Moreover, when using sparse attention kernels to extend its receptive field and per source fine-tuning, we achieve state-of-the-art 9.20 dB of SDR.
Samples are available on our sample page. Checkout [our paper][htdemucs] for more information. It has been trained on the [MUSDB HQ][musdb] dataset + an extra training dataset of 800 songs. This model separates drums, bass and vocals and other stems for any song.
As Hybrid Transformer Demucs is brand new, it is not activated by default, you can activate it in the usual
commands described hereafter with -n htdemucs_ft.
The single, non fine-tuned model is provided as -n htdemucs, and the retrained baseline
as -n hdemucs_mmi. The Sparse Hybrid Transformer model decribed in our paper is not provided as its
requires custom CUDA code that is not ready for release yet.
We are also releasing an experimental 6 sources model, that adds a guitar and piano source.
Quick testing seems to show okay quality for guitar, but a lot of bleeding and artifacts for the piano source.
The list of pre-trained models is:
- htdemucs: first version of Hybrid Transformer Demucs. Trained on MusDB + 800 songs. Default model.
- htdemucs_ft: fine-tuned version of htdemucs, separation will take 4 times more time
but might be a bit better. Same training set as htdemucs.
- htdemucs_6s: 6 sources version of htdemucs, with piano and guitar being added as sources.
Note that the piano source is not working great at the moment.
- hdemucs_mmi: Hybrid Demucs v3, retrained on MusDB + 800 songs.
- mdx: trained only on MusDB HQ, winning model on track A at the [MDX][mdx] challenge.
- mdx_extra: trained with extra training data (including MusDB test set), ranked 2nd on the track B of the [MDX][mdx] challenge.
- mdx_q, mdx_extra_q: quantized version of the previous models. Smaller download and storage
but quality can be slightly worse.
How to cite
@inproceedings{rouard2022hybrid,
title={Hybrid Transformers for Music Source Separation},
author={Rouard, Simon and Massa, Francisco and D{\'e}fossez, Alexandre},
booktitle={ICASSP 23},
year={2023}
}
@inproceedings{defossez2021hybrid,
title={Hybrid Spectrogram and Waveform Source Separation},
author={D{\'e}fossez, Alexandre},
booktitle={Proceedings of the ISMIR 2021 Workshop on Music Source Separation},
year={2021}
}