
Readme
LoraHub: Efficient Cross-Task Generalization via Dynamic LoRA Composition
🏴 Overview
Low-rank adaptations (LoRA) are techniques for fine-tuning large language models on new tasks. We propose LoraHub, a framework that allows composing multiple LoRA modules trained on different tasks. The goal is to achieve good performance on unseen tasks using just a few examples, without needing extra parameters or training. And we want to build a marketplace where users can share their trained LoRA modules, thereby facilitating the application of these modules to new tasks.

The figure demostrates the zero-shot learning, few-shot in-context learning and few-shot lorahub learning (ours). Note that the Compose procedure is conducted per task rather than per example. Our method achieves similar inference throughput as zero-shot learning, yet approaches the performance of in-context learning on the BIG-Bench Hard (BBH) benchmark. The experimental results show the superior efficacy of our method in comparison to zero-shot learning while closely resembling the performance of in-context learning (ICL) in few-shot scenarios.
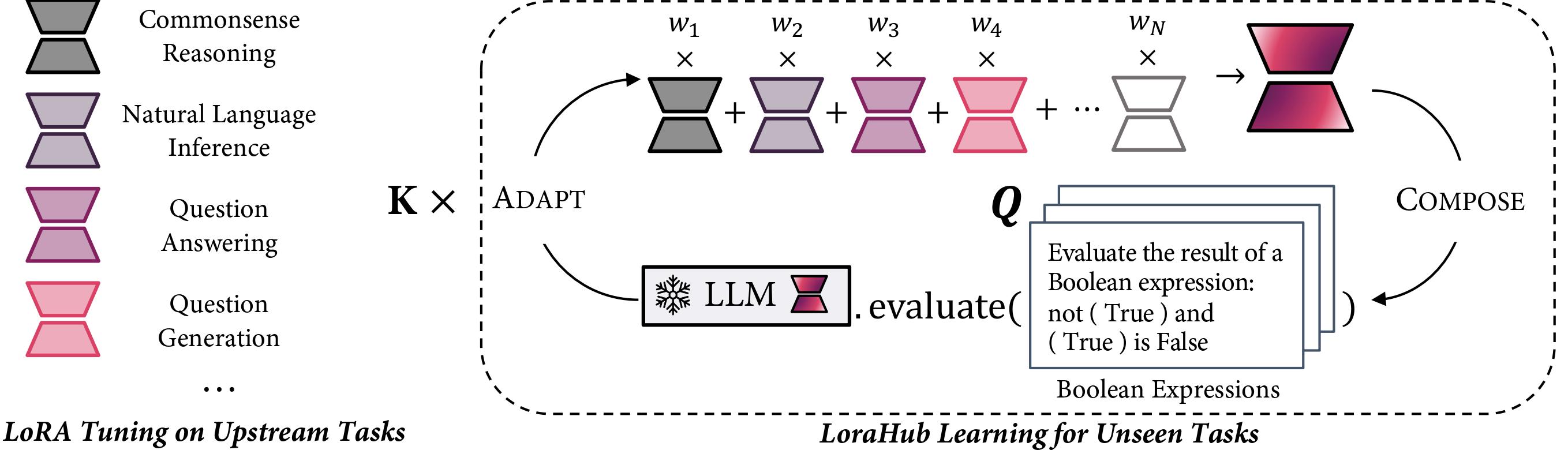
The figure shows the pipeline of LoraHub Learning. Our method encompasses two stages: the Compose stage and the Adapt stage. During the Compose stage, existing LoRA modules are integrated into one unified module, employing a set of weights, denoted as w, as coefficients. In the Adapt stage, the amalgamated LoRA module is evaluated on a few examples from the unseen task. Subsequently, a gradient-free algorithm is applied to refine w. After executing K iterations, a highly adapted LoRA module is produced, which can be incorporated with the LLM to perform the intended task.
🏰 Resource
LoRA Candidates
Our methodology requires a compendium of LoRA modules trained on preceding tasks. For parity with Flan, we adopt the tasks utilized to instruct Flan-T5, thereby incorporating nearly 196 distinct tasks and their corresponding instructions via https://huggingface.co/datasets/conceptofmind/FLAN_2022. Following this, we created several LoRA modules as possible candidates. These LoRA modules can be accessed at https://huggingface.co/models?search=lorahub.
💬 Citation
If our work is useful for you, please consider citing our paper:
@misc{huang2023lorahub,
title={LoraHub: Efficient Cross-Task Generalization via Dynamic LoRA Composition},
author={Chengsong Huang and Qian Liu and Bill Yuchen Lin and Tianyu Pang and Chao Du and Min Lin},
year={2023},
eprint={2307.13269},
archivePrefix={arXiv},
primaryClass={cs.CL}
}