
SDXL is a text-to-image generative AI model developed by Stability AI that creates beautiful images. It is the successor to Stable Diffusion.
Features
Text-to-image generation
To generates images, enter a prompt and run the model.
Image in-painting
SDXL supports in-painting, which lets you “fill in” parts of an existing image with generated content.
- Enter a
promptfor the in-painted pixels - Select an input image in the
imagefield - In the
maskfield, select a black-and-white mask image of the same shape as the input image. All white pixels will be in-painted according to the prompt, which black pixels will be preserved.
Image-to-image generation
Image-to-image lets you start with an input image and transform it “towards” a prompt. For example, you can transform a children’s drawing of castle to a photorealistic castle.
- Enter a
promptthat describes what you want the output image to look like - Select an input image in the
imagefield - The
prompt_strengthfield changes how strongly the prompt is applied to the input image
Refinement
With SDXL you can use a separate refiner model to add finer detail to your output.
You can use the refiner in two ways:
- As an ensemble of experts
- One after the other (
base_model_refineroption)
Ensemble of experts
- In this mode the SDXL base model handles the steps at the beginning (high noise), before handing over to the refining model for the final steps (low noise)
- You get a more detailed image from fewer steps
- You can change the point at which that handover happens, we default to 0.8 (80%)
One after the other
- In this mode you take your final output from SDXL base model and pass it to the refiner
- You can define how many steps the refiner takes
Fine-tuning
You can fine-tune SDXL using the Replicate fine-tuning API. Many languages are supported, but in this example we’ll use the Python SDK:
import replicate
training = replicate.trainings.create(
version="stability-ai/sdxl:39ed52f2a78e934b3ba6e2a89f5b1c712de7dfea535525255b1aa35c5565e08b",
input={
"input_images": "https://my-domain/my-input-images.zip",
},
destination="my-name/my-model"
)
Before fine-tuning starts, the input images are preprocessed using SwinIR for upscaling, BLIP for captioning, and CLIPSeg for removing regions of the images that are not interesting or helpful for training.
Below is a list of all fine-tuning parameters.
Training inputs
input_images(required): A .zip or .tar file containing the image files that will be used for fine-tuning.seed: Random seed integer for reproducible training. Leave empty to use a random seed.resolution: Square pixel resolution which your images will be resized to for training. Defaults to512.train_batch_size: Batch size (per device) for training. Defaults to4.num_train_epochs: Number of epochs to loop through your training dataset. Defaults to4000.max_train_steps: Number of individual training steps. Takes precedence over num_train_epochs. Defaults to1000.is_lora: Boolean indicating whether to use LoRA training. If set to False, will use Full fine tuning. Defaults toTrue.unet_learning_rate: Learning rate for the U-Net as a float. We recommend this value to be somewhere between1e-6: to1e-5. Defaults to1e-6.ti_lr: Scaling of learning rate for training textual inversion embeddings. Don’t alter unless you know what you’re doing. Defaults to3e-4.lora_lr: Scaling of learning rate for training LoRA embeddings. Don’t alter unless you know what you’re doing. Defaults to1e-4.lr_scheduler: Learning rate scheduler to use for training. Allowable values areconstantorlinear. Defaults toconstant.lr_warmup_steps: Number of warmup steps for lr schedulers with warmups. Defaults to100.token_string: A unique string that will be trained to refer to the concept in the input images. Can be anything, but TOK works well. Defaults toTOK.caption_prefix: Text which will be used as prefix during automatic captioning. Must contain thetoken_string. For example, if caption text is ‘a photo of TOK’, automatic captioning will expand to ‘a photo of TOK under a bridge’, ‘a photo of TOK holding a cup’, etc.”, Defaults toa photo of TOK.mask_target_prompts: Prompt that describes part of the image that you will find important. For example, if you are fine-tuning your pet,photo of a dogwill be a good prompt. Prompt-based masking is used to focus the fine-tuning process on the important/salient parts of the image. Defaults to None.crop_based_on_salience: If you want to crop the image totarget_size: based on the important parts of the image, set this to True. If you want to crop the image based on face detection, set this to False. Defaults toTrue.use_face_detection_instead: If you want to use face detection instead of CLIPSeg for masking. For face applications, we recommend using this option. Defaults toFalse.clipseg_temperature: How blurry you want the CLIPSeg mask to be. We recommend this value be something between0.5: to1.0. If you want to have more sharp mask (but thus more errorful), you can decrease this value. Defaults to1.0.verbose: Verbose output. Defaults toTrue.checkpointing_steps: Number of steps between saving checkpoints. Set to very very high number to disable checkpointing, because you don’t need one. Defaults to200.
Model Description
- Developed by: Stability AI
- Model type: Diffusion-based text-to-image generative model
- License: CreativeML Open RAIL++-M License
- Model Description: This is a model that can be used to generate and modify images based on text prompts. It is a Latent Diffusion Model that uses two fixed, pretrained text encoders (OpenCLIP-ViT/G and CLIP-ViT/L).
- Resources for more information: Check out our GitHub Repository and the SDXL report on arXiv.
Evaluation
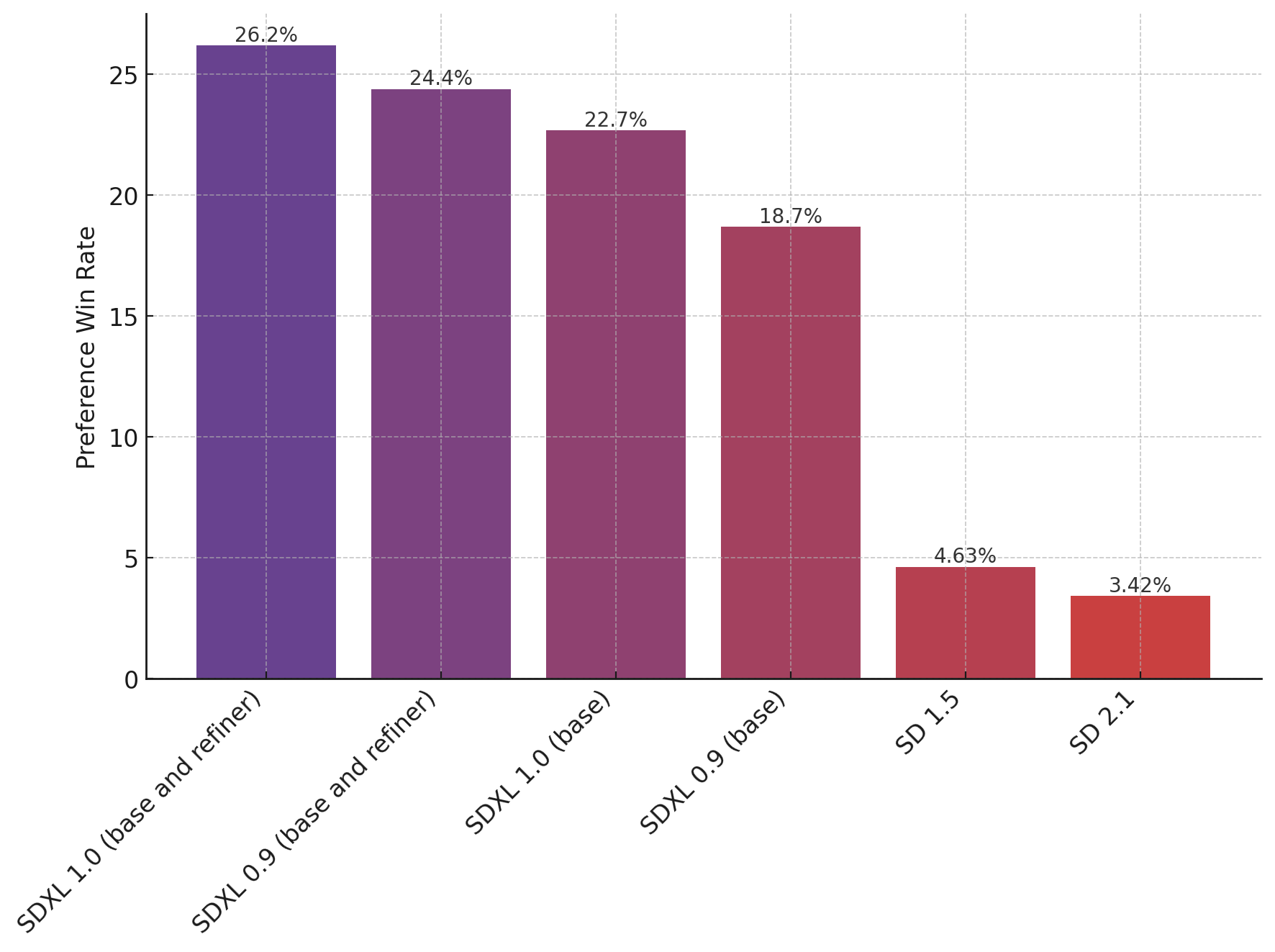
The chart above evaluates user preference for SDXL (with and without refinement) over SDXL 0.9 and Stable Diffusion 1.5 and 2.1. The SDXL base model performs significantly better than the previous variants, and the model combined with the refinement module achieves the best overall performance.
Uses
Direct Use
The model is intended for research purposes only. Possible research areas and tasks include
- Generation of artworks and use in design and other artistic processes.
- Applications in educational or creative tools.
- Research on generative models.
- Safe deployment of models which have the potential to generate harmful content.
- Probing and understanding the limitations and biases of generative models.
- Excluded uses are described below.
Out-of-Scope Use
The model was not trained to be factual or true representations of people or events, and therefore using the model to generate such content is out-of-scope for the abilities of this model.
Limitations and Bias
Limitations
- The model does not achieve perfect photorealism
- The model cannot render legible text
- The model struggles with more difficult tasks which involve compositionality, such as rendering an image corresponding to “A red cube on top of a blue sphere”
- Faces and people in general may not be generated properly.
- The autoencoding part of the model is lossy.
Bias
- While the capabilities of image generation models are impressive, they can also reinforce or exacerbate social biases.
Architecture
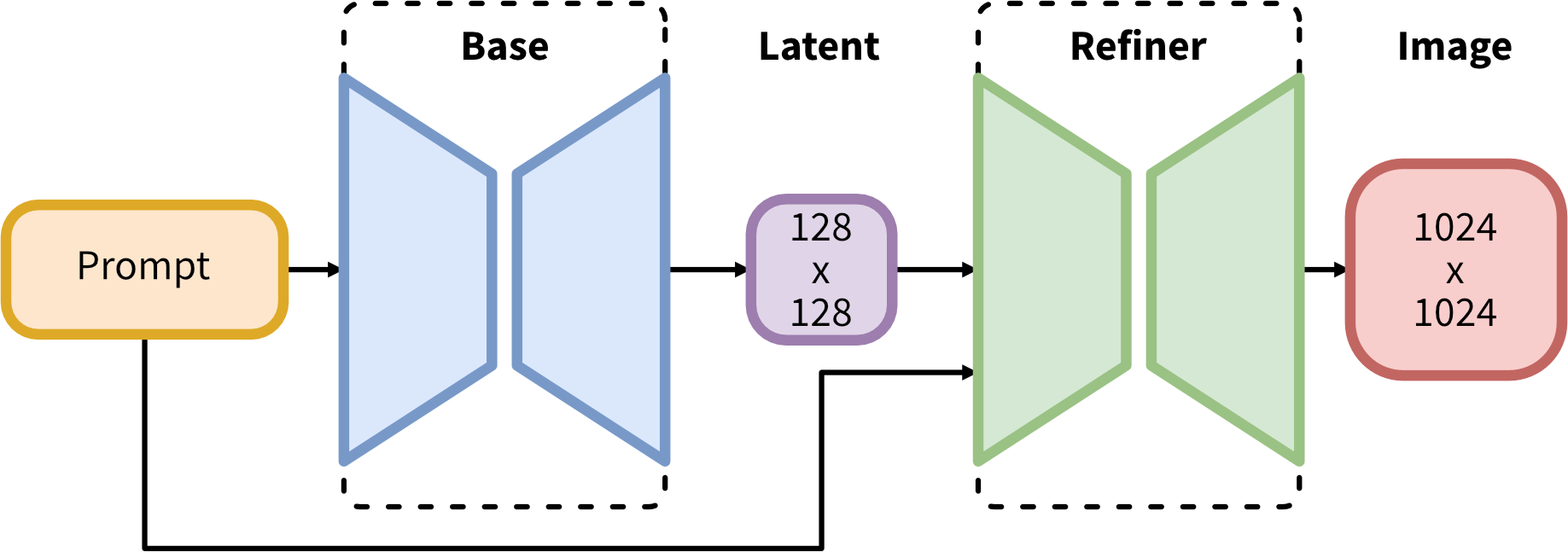
SDXL consists of a mixture-of-experts pipeline for latent diffusion: In a first step, the base model is used to generate (noisy) latents, which are then further processed with a refinement model (available here: https://huggingface.co/stabilityai/stable-diffusion-xl-refiner-1.0/) specialized for the final denoising steps. Note that the base model can be used as a standalone module.
Alternatively, we can use a two-stage pipeline as follows: First, the base model is used to generate latents of the desired output size. In the second step, we use a specialized high-resolution model and apply a technique called SDEdit (https://arxiv.org/abs/2108.01073, also known as “img2img”) to the latents generated in the first step, using the same prompt. This technique is slightly slower than the first one, as it requires more function evaluations.