Documentation
Replicate lets you run AI models with a cloud API, without having to understand machine learning or manage your own infrastructure.
You can run open-source models that other people have published, bring your own training data to create fine-tuned models , or build and publish custom models from scratch.
Get started
Try out Replicate quickly in your environment of choice




Topics
Learn about the building blocks that make Replicate work




Guides
Ready to build something? Check out these guides to level up your AI skills





Videos
Prefer to learn by watching videos? Check out some recent demos from our YouTube channel
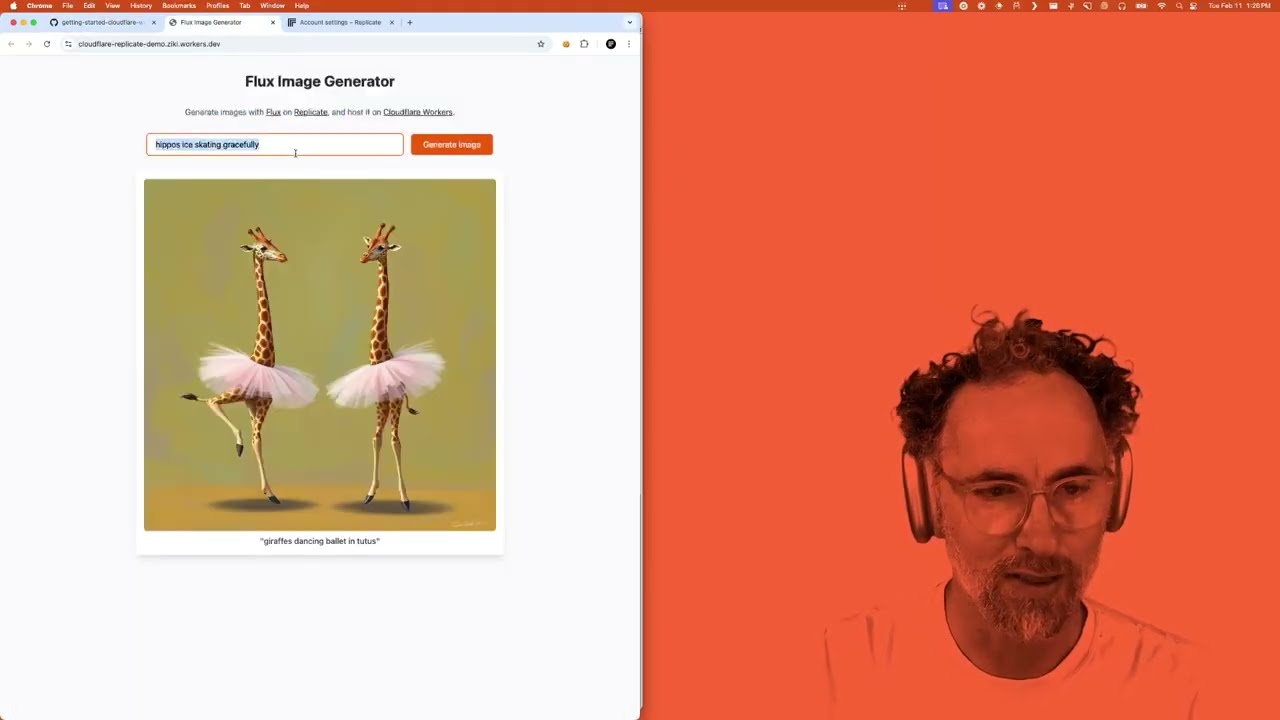
Run Replicate models using Cloudflare Workers
Create and deploy a web app with a serverless backend and a React frontend in under 60 seconds.
7 minutes
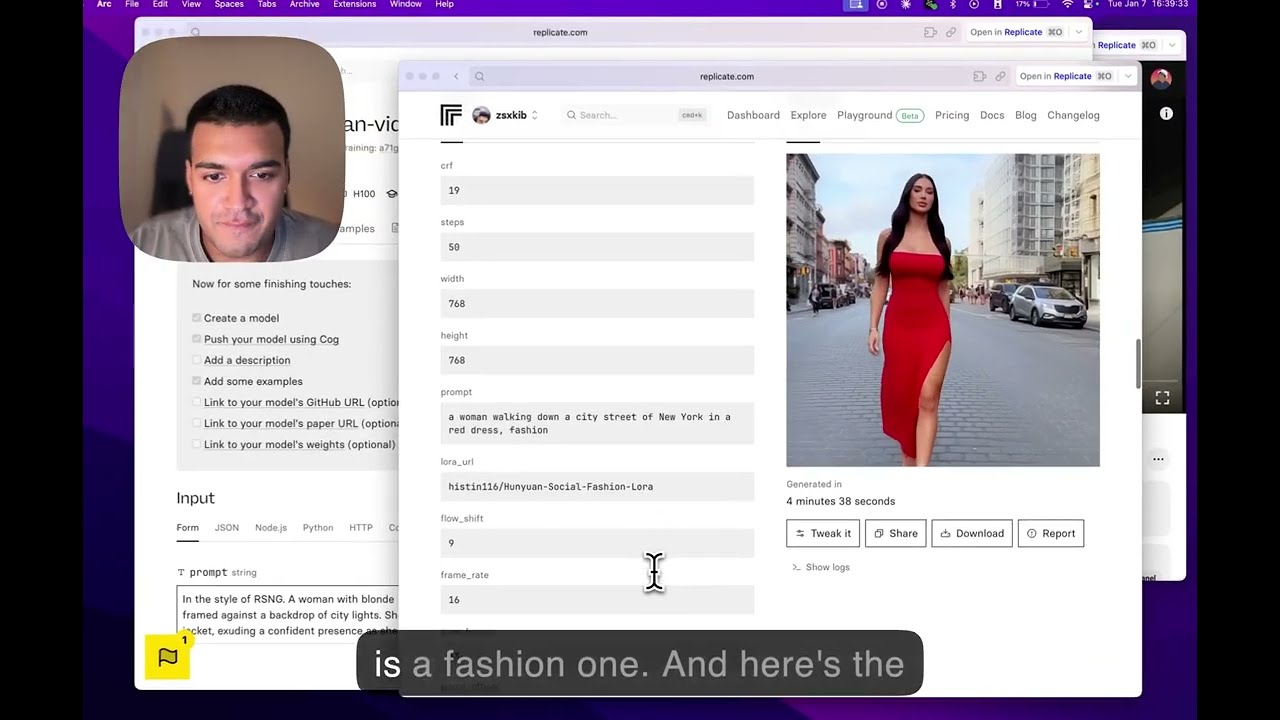
Create stylized videos using pre-trained HuggingFace LoRAs
Make video content using the Hunyuan model with pre-trained styles from HuggingFace, or using your own images as training data.
3 minutes
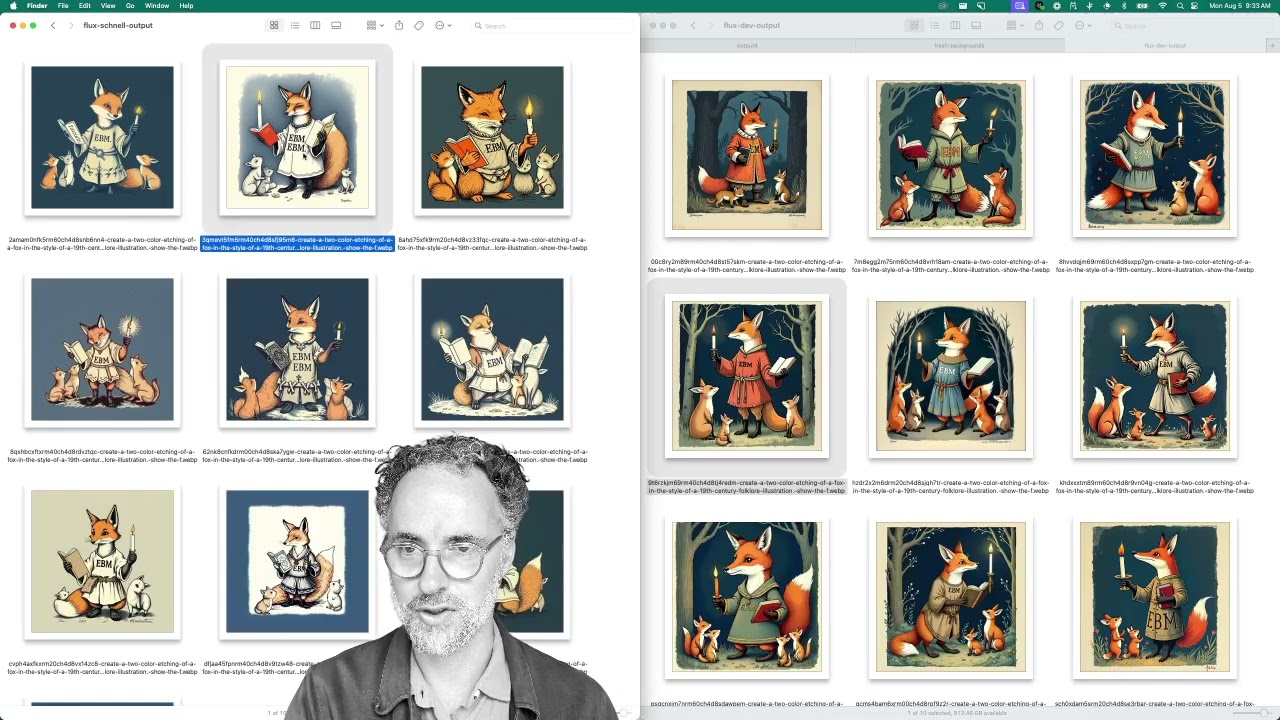
FLUX.1 Schnell vs FLUX.1 Dev
Explore the differences between Flux Schnell and Flux Dev image generation models and learn how to enhance image quality effectively.
6 minutes
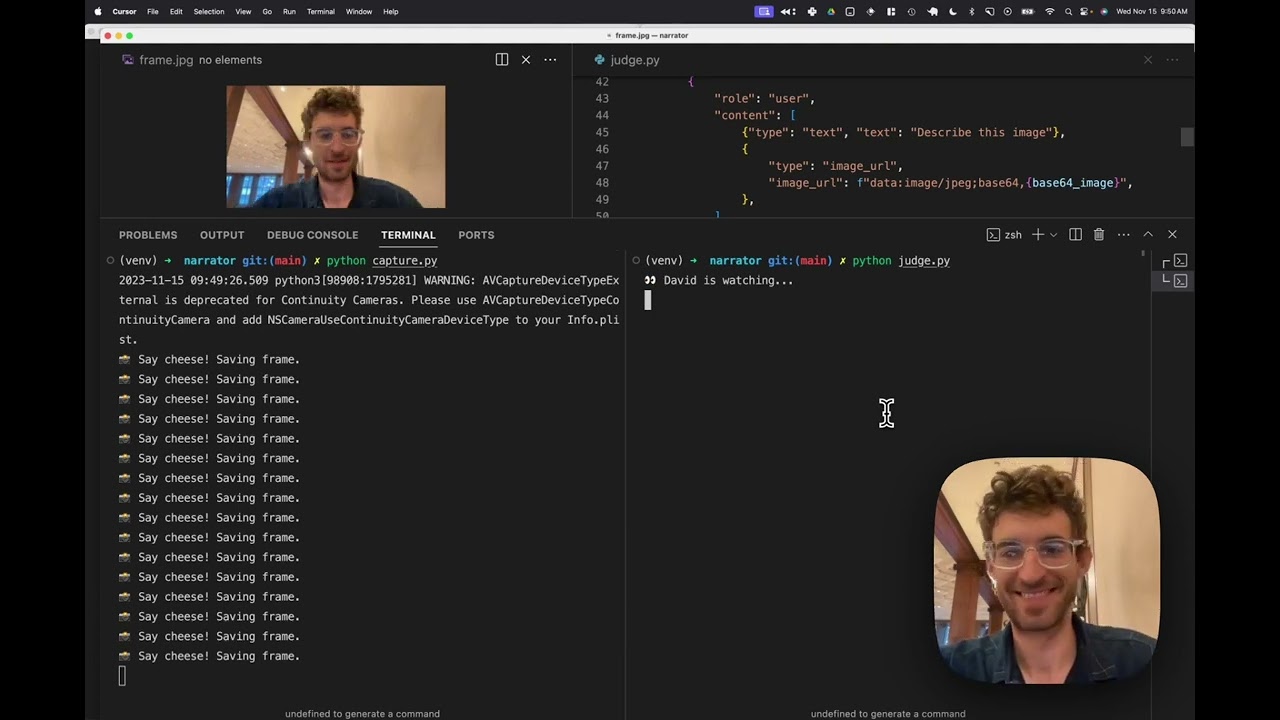
David Attenborough is now narrating my life
Here's a GPT-4-vision + ElevenLabs python script so you can star in your own Planet Earth.
2 minutes
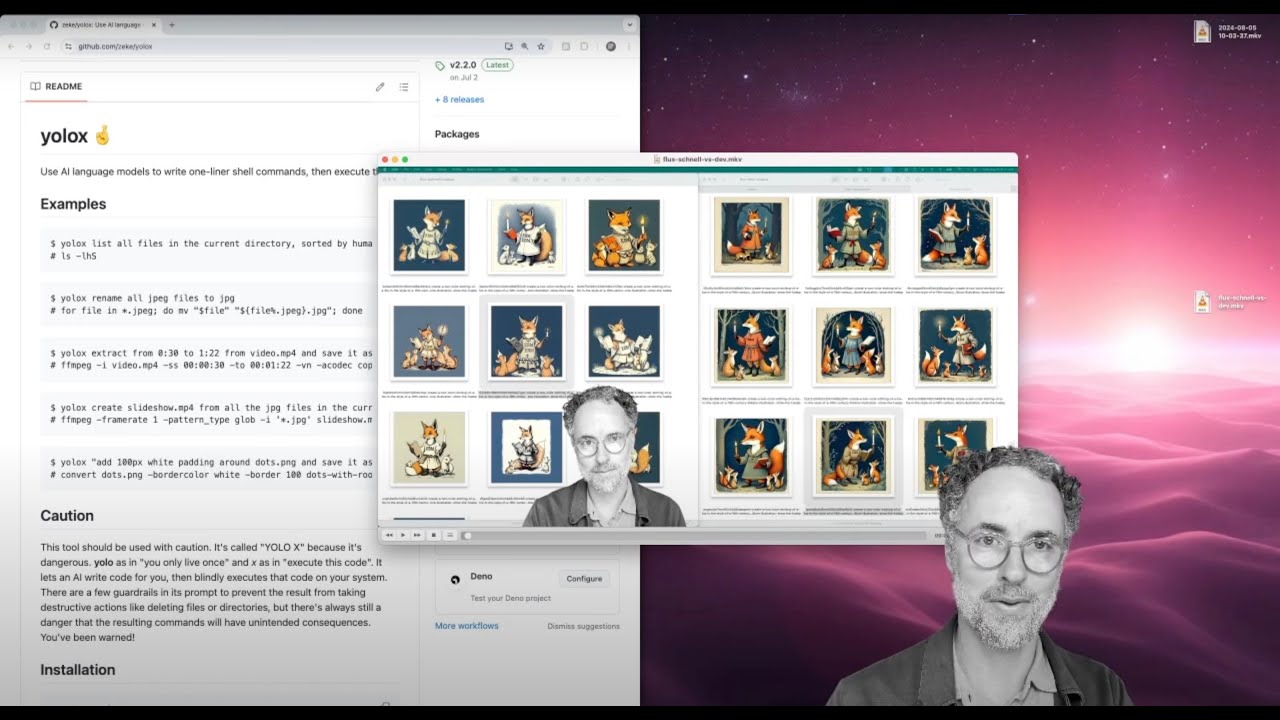
Write your shell commands in English
Use language models like GPT-4o and Llama to write one-liner shell commands, then execute them.
4 minutes
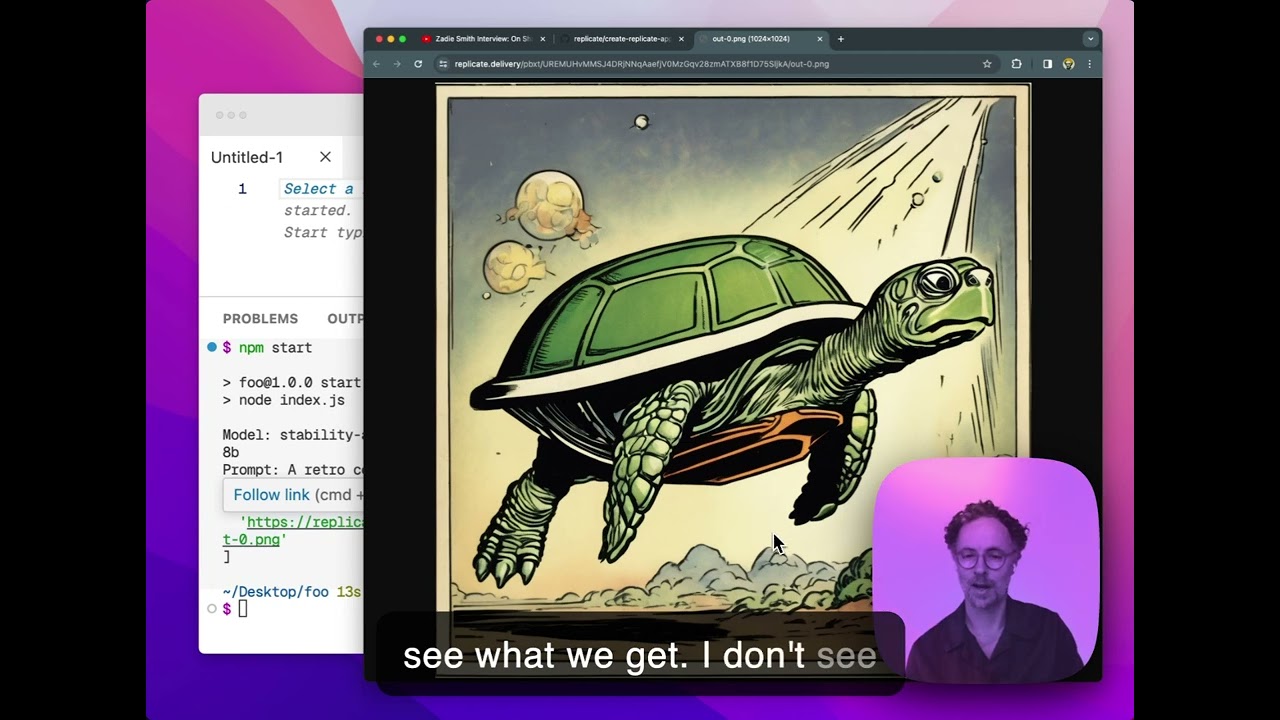
Introducing create-replicate-app
A quick and easy way to run Replicate models with Node.js
3 minutes
Using webhooks with Replicate's API
Learn how to receive webhooks from Replicate's API when running predictions and trainings.
14 minutes