Explore
Featured models

black-forest-labs / flux-canny-pro
Professional edge-guided image generation. Control structure and composition using Canny edge detection

black-forest-labs / flux-fill-pro
Professional inpainting and outpainting model with state-of-the-art performance. Edit or extend images with natural, seamless results.

black-forest-labs / flux-1.1-pro-ultra
FLUX1.1 [pro] in ultra and raw modes. Images are up to 4 megapixels. Use raw mode for realism.

black-forest-labs / flux-redux-dev
Open-weight image variation model. Create new versions while preserving key elements of your original.

recraft-ai / recraft-v3
Recraft V3 (code-named red_panda) is a text-to-image model with the ability to generate long texts, and images in a wide list of styles. As of today, it is SOTA in image generation, proven by the Text-to-Image Benchmark by Artificial Analysis
ibm-granite / granite-3.0-8b-instruct
Granite-3.0-8B-Instruct is a lightweight and open-source 8B parameter model is designed to excel in instruction following tasks such as summarization, problem-solving, text translation, reasoning, code tasks, function-calling, and more.
I want to…
Generate images
Models that generate images from text prompts
Use a language model
Models that can understand and generate text
Upscale images
Upscaling models that create high-quality images from low-quality images
Caption images
Models that generate text from images
The FLUX family of models
The FLUX family of text-to-image models from Black Forest Labs
Restore images
Models that improve or restore images by deblurring, colorization, and removing noise
Get embeddings
Models that generate embeddings from inputs
Extract text from images
Optical character recognition (OCR) and text extraction
Transcribe speech
Models that convert speech to text
Use handy tools
Toolbelt-type models for videos and images.
Chat with images
Ask language models about images
Edit images
Tools for manipulating images.
Use a face to make images
Make realistic images of people instantly
Flux fine-tunes
Browse the diverse range of fine-tunes the community has custom-trained on Replicate
Generate music
Models to generate and modify music
Generate videos
Models that create and edit videos
Generate speech
Convert text to speech
Make 3D stuff
Models that generate 3D objects, scenes, radiance fields, textures and multi-views.
Get structured data
Language models that support grammar-based decoding as well as jsonschema constraints.
Popular models

A simple OCR Model that can easily extract text from an image.

SDXL-Lightning by ByteDance: a fast text-to-image model that makes high-quality images in 4 steps

Fine-Tuned Vision Transformer (ViT) for NSFW Image Classification



Real-ESRGAN with optional face correction and adjustable upscale


A text-to-image generative AI model that creates beautiful images
Latest models


A LoRA fine tuned version of SDXL trained on late legendary Indian artist Bapu's art work



RealVisXl V3 with multi-controlnet, lora loading, img2img, inpainting

Source: pipizhao/Pandalyst-7B-V1.2 ✦ Quant: TheBloke/Pandalyst-7B-v1.2-AWQ ✦ Pandalyst: A large language model for mastering data analysis using pandas


RESEARCH/NON-COMMERCIAL USE ONLY: High-Quality Image-to-Video Synthesis via Cascaded Diffusion Models


This is the chat model finetuned on top of TinyLlama/TinyLlama-1.1B-intermediate-step-1431k-3T

🗣️ Nvidia + Suno.ai's speech-to-text conversion with high accuracy and efficiency 📝





Stable Diffusion XL fine-tunned in the theme of Anime Schoolboy

Versatile Audio Super-resolution at Scale which upsamples audio files to 48khz. Longer audio input is possible with this model


Stable Diffusion XL fine-tunned in the theme of Anime Schoolgirl

Source: TinyLlama/TinyLlama-1.1B-Chat-v1.0 ✦ Quant: TheBloke/TinyLlama-1.1B-Chat-v1.0-AWQ ✦ The TinyLlama project is an open endeavor to pretrain a 1.1B Llama model on 3 trillion tokens.


PyTSMod is an open-source library for Time-Scale Modification(eg. time-stretching) algorithms, by Sangeon Yong at MAC Lab, KAIST.

Zero-shot classifier which classifies text into categories of your choosing. Returns a dictionary of the most likely class and all class likelihoods.

Nous Hermes 2 - SOLAR 10.7B is the flagship Nous Research model on the SOLAR 10.7B base model..

Nous Hermes 2 - SOLAR 10.7B is the flagship Nous Research model on the SOLAR 10.7B base model.



Source: Arc53/docsgpt-7b-mistral ✦ Quant: TheBloke/docsgpt-7B-mistral-AWQ ✦ DocsGPT is optimized for Documentation (RAG), fine-tuned for providing answers that are based on context

GFPGAN aims at developing Practical Algorithms for Real-world Face Restoration

Better than SDXL at both prompt adherence and image quality, by dataautogpt3


this is the replicate version of singing_voice_conversion from amphion

Animagine XL 2.0 is an advanced latent text-to-image diffusion model designed to create high-resolution, detailed anime images.

ElasticDiffusion: Training-free Arbitrary Size Image Generation
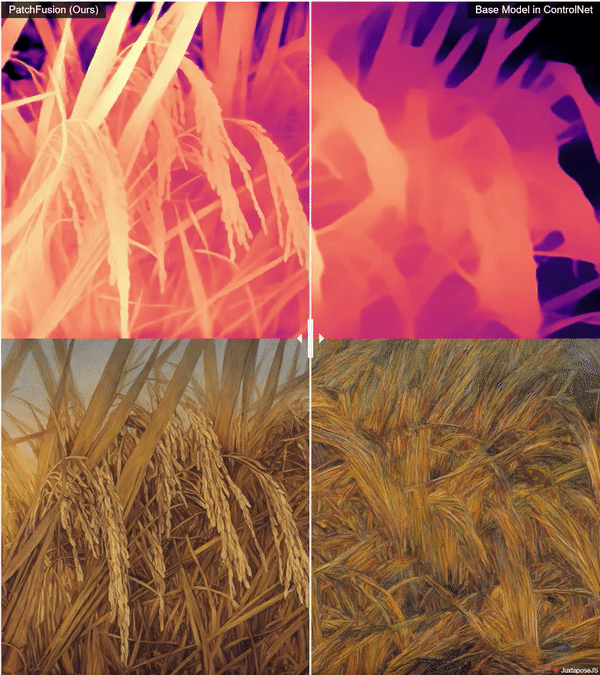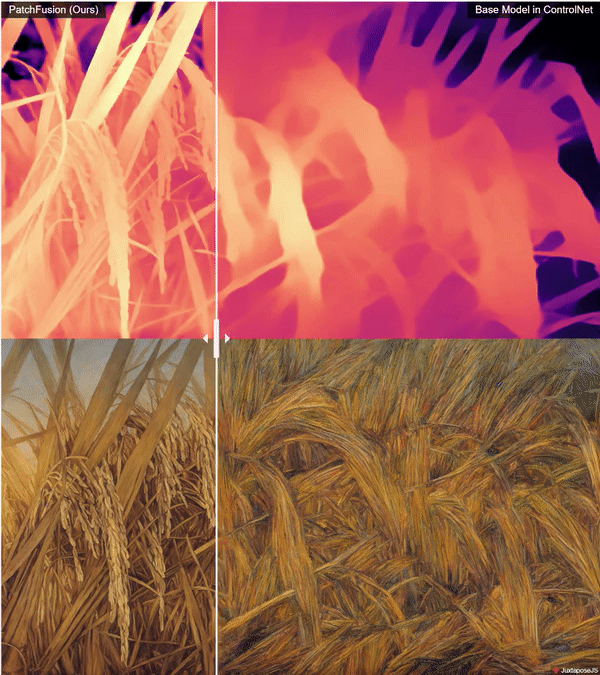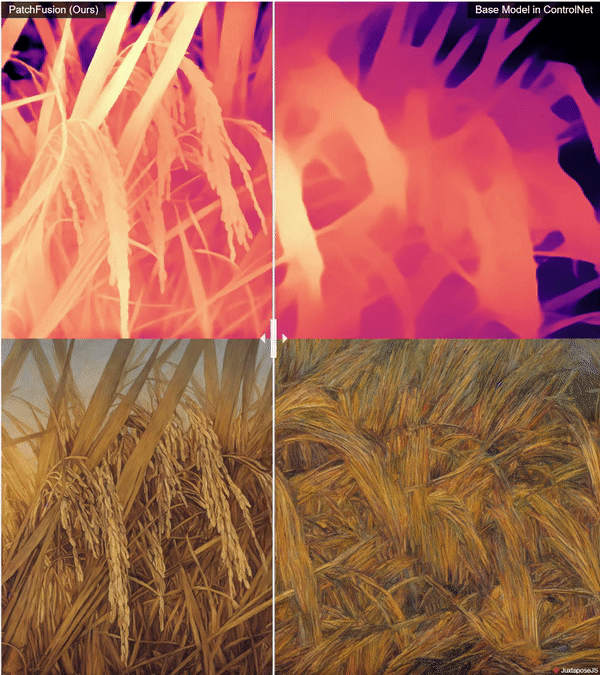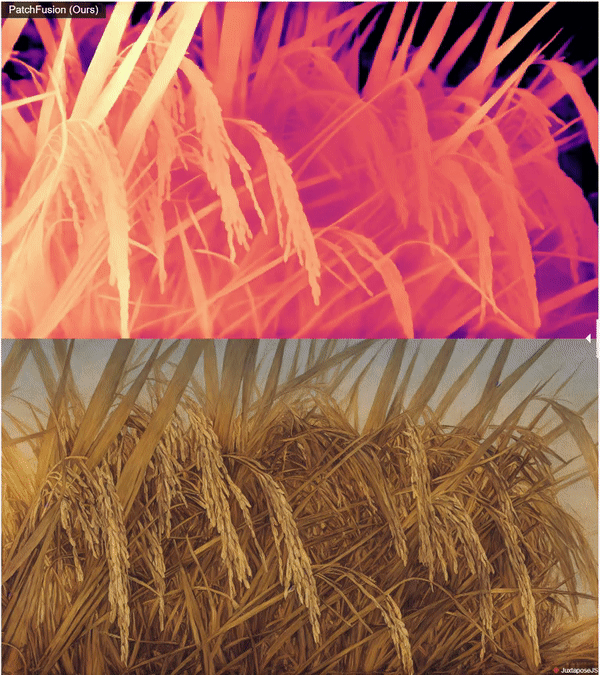
Super High Quality Depth Maps 🗺️: An End-to-End Tile-Based Framework 🏗️ for High-Resolution Monocular Metric Depth Estimation 🔍📏

A unique fusion that showcases exceptional prompt adherence and semantic understanding, it seems to be a step above base SDXL and a step closer to DALLE-3 in terms of prompt comprehension

Space-Time Diffusion Features for Zero-Shot Text-Driven Motion Transfer

Nous Hermes 2 - Yi-34B is a state of the art Yi Fine-tune, fine tuned on GPT-4 generated synthetic data

Terminus XL Otaku is a latent diffusion model that uses zero-terminal SNR noise schedule and velocity prediction objective at training and inference time.

works with inpainting and multi-controlnet + single-controlnet || ip-adapter + without ip adapter


Terminus XL Gamma is a new state-of-the-art latent diffusion model that uses zero-terminal SNR noise schedule and velocity prediction objective at training and inference time.

Fine-tune of music gen with tracks from my record label Dream In Audio.

Source: SuperAGI/SAM ✦ Quant: TheBloke/SAM-AWQ ✦ SAM (Small Agentic Model), a 7B model that demonstrates impressive reasoning abilities despite its smaller size

RealvisXL3 fine-tuned on 300+ colorized 1850s-1940s photos

