Explore


beautyyuyanli / multilingual-e5-large
multilingual-e5-large: A multi-language text embedding model
43.5M runs


jaaari / kokoro-82m
Kokoro v1.0 - text-to-speech (82M params, based on StyleTTS2)
68.6M runs


tencentarc / gfpgan
Practical face restoration algorithm for *old photos* or *AI-generated faces*
103.7M runs


prunaai / flux-kontext-fast
Ultra fast flux kontext endpoint
14.8M runs
Featured models

 openai/gpt-image-1.5
openai/gpt-image-1.5OpenAI's latest image generation model with better instruction following and adherence to prompts
1.9K runs

 black-forest-labs/flux-2-max
black-forest-labs/flux-2-maxThe highest fidelity image model from Black Forest Labs
2.5K runs

The fastest open source TTS model without sacrificing quality.
1.6K runs
 openai/gpt-5.2
openai/gpt-5.2The best model for coding and agentic tasks across industries
119.3K runs

 bytedance/seedream-4.5
bytedance/seedream-4.5Seedream 4.5: Upgraded Bytedance image model with stronger spatial understanding and world knowledge
203.8K runs
 prunaai/z-image-turbo
prunaai/z-image-turboZ-Image Turbo is a super fast text-to-image model of 6B parameters developed by Tongyi-MAI.
690.5K runs
 lightricks/ltx-2-retake
lightricks/ltx-2-retakeTake any shot and edit specific sections. Rephrase, change the action, camera angles and more
674 runs

 google/gemini-3-pro
google/gemini-3-proGoogle's most advanced reasoning Gemini model
51.5K runs
 google/nano-banana-pro
google/nano-banana-proGoogle's state of the art image generation and editing model 🍌🍌
4.8M runs
 prunaai/p-image-edit
prunaai/p-image-editA sub 1 second 0.01$ multi-image editing model built for production use cases. For image generation, check out p-image here: https://replicate.com/prunaai/p-image
868.1K runs
google/veo-3.1New and improved version of Veo 3, with higher-fidelity video, context-aware audio, reference image and last frame support
194.6K runs

 philz1337x/crystal-upscaler
philz1337x/crystal-upscalerHigh-precision image upscaler optimized for portraits, faces and products. One of the upscale modes powered by Clarity AI. X:https://x.com/philz1337x
260.8K runs
Official models
Official models are always on, maintained, and have predictable pricing.
openai / gpt-image-1.5
OpenAI's latest image generation model with better instruction following and adherence to prompts
black-forest-labs / flux-2-max
The highest fidelity image model from Black Forest Labs
wan-video / wan-2.6-i2v
Alibaba Wan 2.6 image to video generation model
wan-video / wan-2.6-t2v
Alibaba Wan 2.6 text to video generation model
resemble-ai / chatterbox-turbo
The fastest open source TTS model without sacrificing quality.
openai / gpt-5.2
The best model for coding and agentic tasks across industries
sync / react-1
Realistic lipsync with refined human emotion capabilities
veed / fabric-1.0
VEED Fabric 1.0 is an image-to-video API that turns any image into a talking video
bytedance / seedream-4.5
Seedream 4.5: Upgraded Bytedance image model with stronger spatial understanding and world knowledge
prunaai / z-image-turbo
Z-Image Turbo is a super fast text-to-image model of 6B parameters developed by Tongyi-MAI.

black-forest-labs / flux-2-flex
Max-quality image generation and editing with support for ten reference images

black-forest-labs / flux-2-dev
Quality image generation and editing with support for reference images
lightricks / ltx-2-retake
Take any shot and edit specific sections. Rephrase, change the action, camera angles and more
google / gemini-3-pro
Google's most advanced reasoning Gemini model

hyper3d / rodin
Generate complex 3D models from images with Rodin Gen-2

black-forest-labs / flux-2-pro
High-quality image generation and editing with support for eight reference images

openai / gpt-5.1
The best model for coding and agentic tasks with configurable reasoning effort.

qwen-edit-apps / qwen-image-edit-plus-lora-fusion
Fusion – Product/object blending that fixes perspective and lighting so the subject melts into a new background via the Fusion LoRA.

qwen-edit-apps / qwen-image-edit-plus-lora-relight
Relight – Soft, curtain-filtered relighting that repaints the scene with golden-hour or moody tones using the Relight LoRA.

qwen-edit-apps / qwen-image-edit-plus-lora-upscale
Upscale – Detail-loving upscale/restore pass that sharpens textures and color fidelity with the Upscale LoRA.
I want to…
View all collectionsGenerate images
Use AI to generate images & photos with an API
Caption videos
Use AI to caption videos with an API
Generate speech
Use AI for text-to-speech or to clone your voice via API
Generate images from a face
Use AI to generate images from a face with an API
Generate videos
Use AI to generate videos with an API
Upscale images with super resolution
Use AI to upscale images with super resolution with an API
Generate music
Use AI to generate music with an API
Edit any image
Use AI to edit any image via API
Transcribe speech to text
Use AI to transcribe speech to text via API
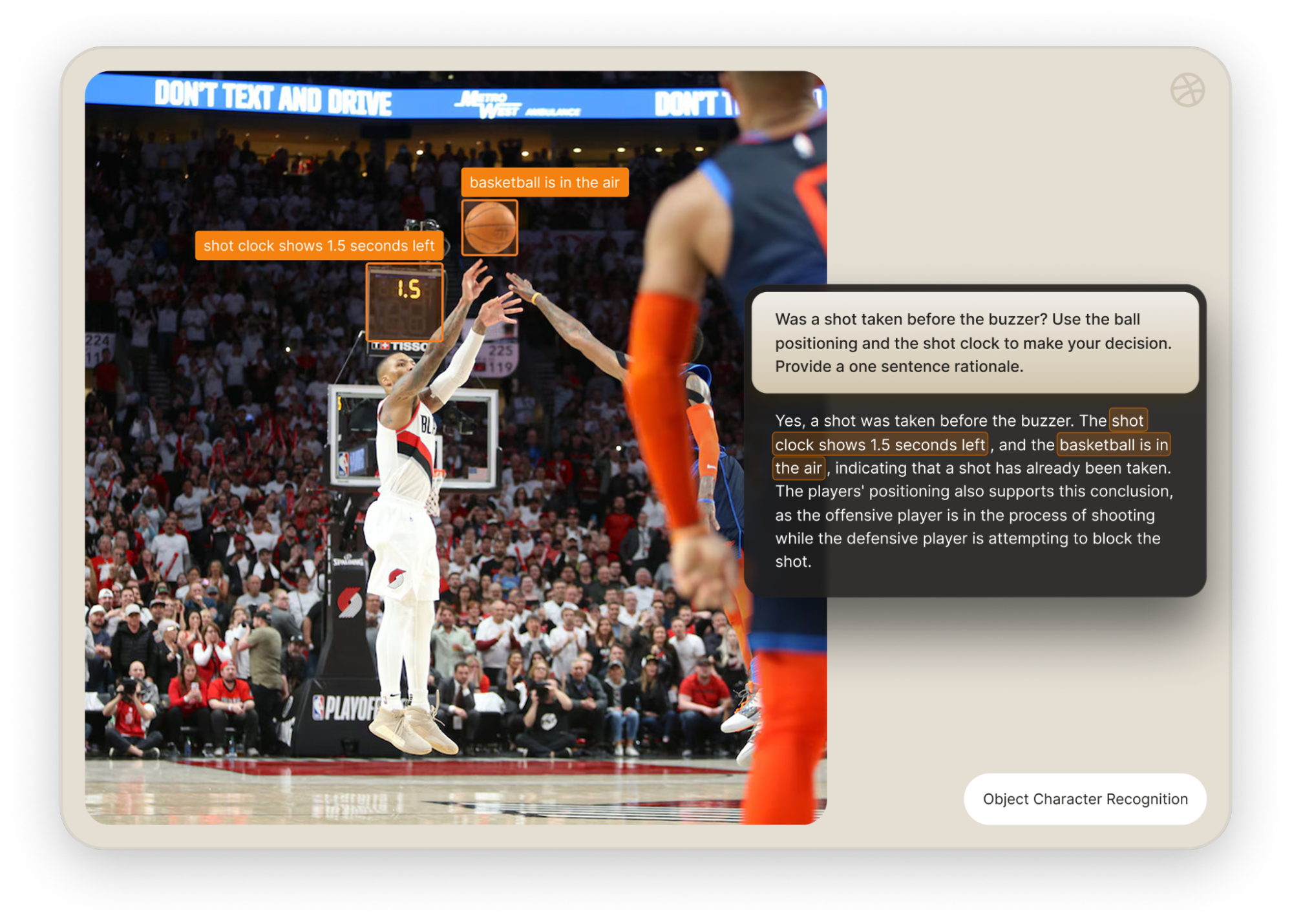
OCR to extract text from images
Use AI For Optical Character Recognition (OCR) to extract text from images via API
Remove backgrounds
Use AI to remove backgrounds from images and videos with an API
FLUX family of models
FLUX AI models: advanced image generation & editing via API
Restore images
Use AI to restore images via API
Enhance videos
Use AI to enhance videos via API - Replicate
Detect NSFW content
Detect NSFW content in images and text
Classify text
Classify text by sentiment, topic, intent, or safety
Speaker diarization
Identify speakers from audio and video inputs
Create realistic face swaps
Replace faces across images with natural-looking results.
Turn sketches into images
Transform rough sketches into polished visuals
Generate emojis
Generate custom emojis from text or images
Generate anime-style images and videos
Create anime-style characters, scenes, and animations
Generate videos from images
Use AI to Generate Videos from Images with API
Lipsync videos
Use AI to generate lipsync videos with an API
Create 3D content
Use AI to create 3D content with an API
Vision models
Chat with images for understanding, captioning & detection via API
Large Language Models (LLMs)
Explore Large Language Models (LLMs) for chat, generation & NLP tasks via API
Try AI models for free
Try AI Models for free: video generation, image generation, upscaling, and photo restoration
Control image generation
Use AI to control image generation with an API
Embedding models
Embedding models for AI search and analysis
Edit your videos
Use AI to edit your videos with an API
Object detection and segmentation
Use AI object detection and segmentation models to distinguish objects in images & videos
Official AI models
Official AI models: Always available, stable, and predictably priced
Flux fine-tunes
Flux fine-tunes: build and run custom AI image models via API
Kontext fine-tunes
Kontext fine-tunes: Build custom AI image models with an API
Create songs with voice cloning
Create songs with voice cloning models via API
Media utilities
AI media utilities: auto-caption, watermark, frame extraction & more via API
Qwen-Image fine-tunes
Browse the diverse range of qwen-image fine-tunes the community has custom-trained on Replicate.
WAN family of models
WAN family of models: powerful image-to-video & text-to-video models
Caption Images
Use AI To Caption Images with an API