Explore
Featured models

black-forest-labs / flux-canny-pro
Professional edge-guided image generation. Control structure and composition using Canny edge detection

black-forest-labs / flux-fill-pro
Professional inpainting and outpainting model with state-of-the-art performance. Edit or extend images with natural, seamless results.

black-forest-labs / flux-1.1-pro-ultra
FLUX1.1 [pro] in ultra and raw modes. Images are up to 4 megapixels. Use raw mode for realism.

black-forest-labs / flux-redux-dev
Open-weight image variation model. Create new versions while preserving key elements of your original.

recraft-ai / recraft-v3
Recraft V3 (code-named red_panda) is a text-to-image model with the ability to generate long texts, and images in a wide list of styles. As of today, it is SOTA in image generation, proven by the Text-to-Image Benchmark by Artificial Analysis
ibm-granite / granite-3.0-8b-instruct
Granite-3.0-8B-Instruct is a lightweight and open-source 8B parameter model is designed to excel in instruction following tasks such as summarization, problem-solving, text translation, reasoning, code tasks, function-calling, and more.
I want to…
Generate images
Models that generate images from text prompts
Use a language model
Models that can understand and generate text
Upscale images
Upscaling models that create high-quality images from low-quality images
Caption images
Models that generate text from images
The FLUX family of models
The FLUX family of text-to-image models from Black Forest Labs
Restore images
Models that improve or restore images by deblurring, colorization, and removing noise
Get embeddings
Models that generate embeddings from inputs
Extract text from images
Optical character recognition (OCR) and text extraction
Transcribe speech
Models that convert speech to text
Use handy tools
Toolbelt-type models for videos and images.
Chat with images
Ask language models about images
Edit images
Tools for manipulating images.
Use a face to make images
Make realistic images of people instantly
Flux fine-tunes
Browse the diverse range of fine-tunes the community has custom-trained on Replicate
Generate music
Models to generate and modify music
Generate videos
Models that create and edit videos
Generate speech
Convert text to speech
Make 3D stuff
Models that generate 3D objects, scenes, radiance fields, textures and multi-views.
Get structured data
Language models that support grammar-based decoding as well as jsonschema constraints.
Popular models

A simple OCR Model that can easily extract text from an image.

SDXL-Lightning by ByteDance: a fast text-to-image model that makes high-quality images in 4 steps

Fine-Tuned Vision Transformer (ViT) for NSFW Image Classification
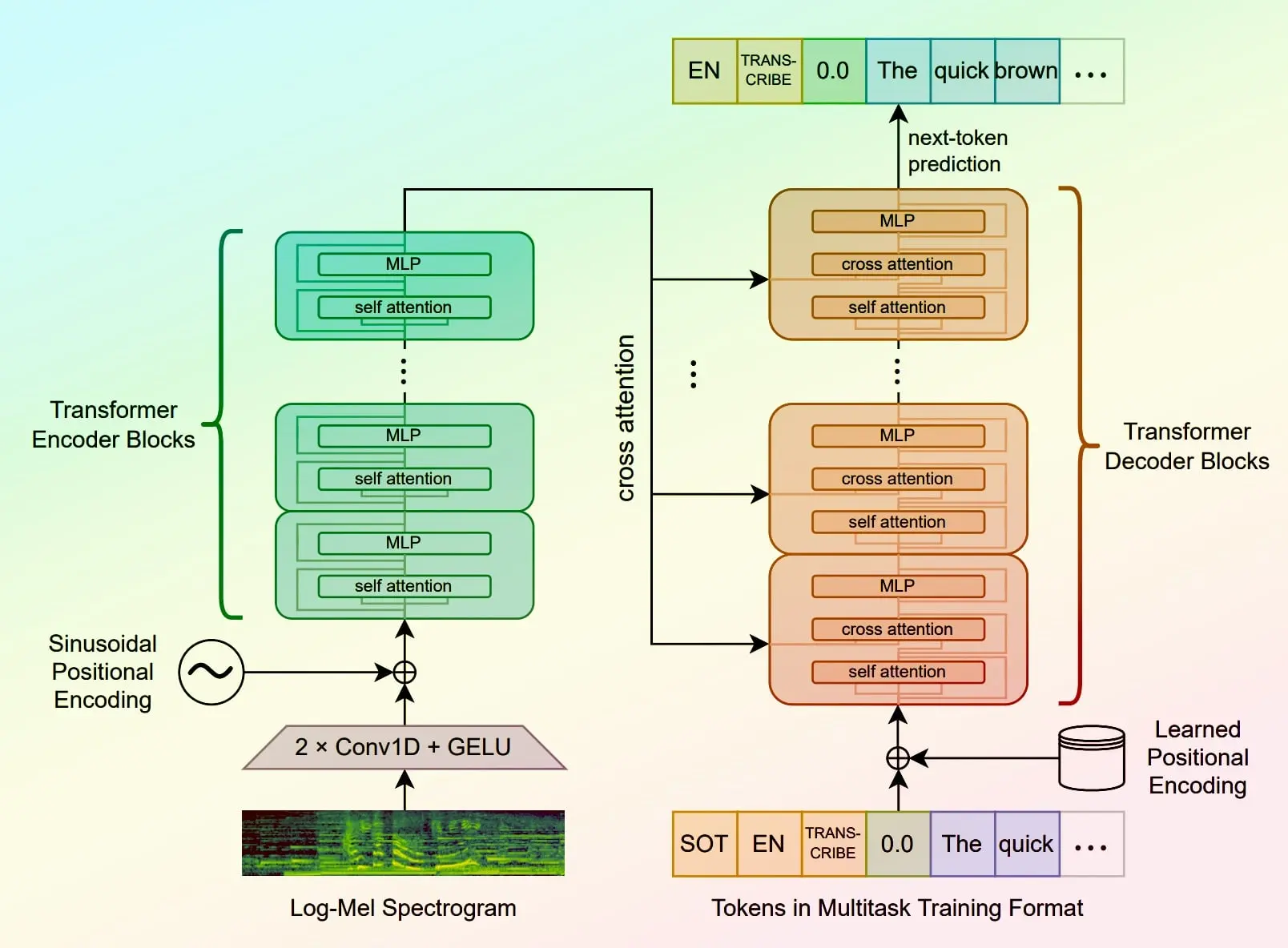

A text-to-image generative AI model that creates beautiful images



Real-ESRGAN with optional face correction and adjustable upscale
Latest models
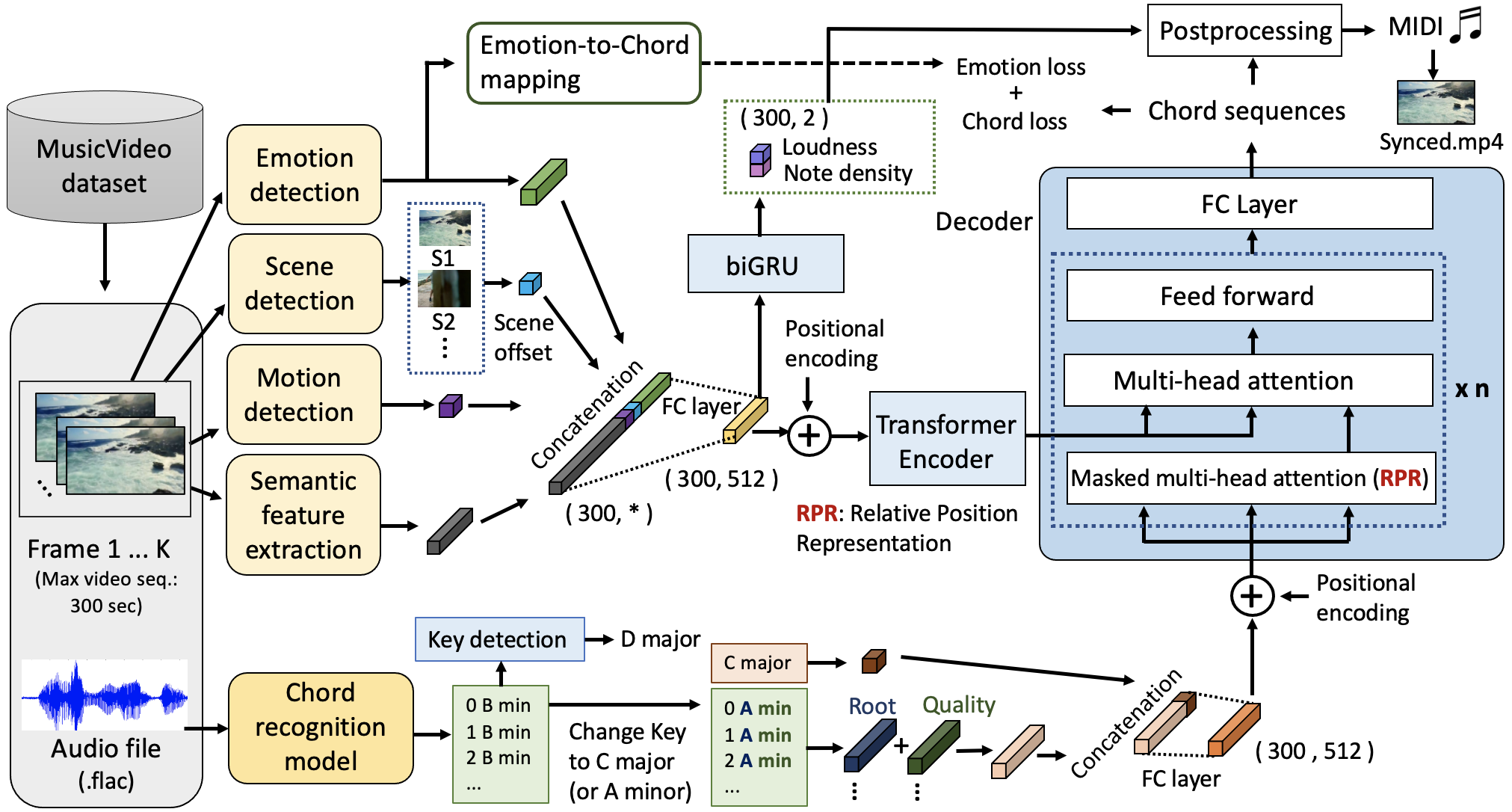
Video2Music: Suitable Music Generation from Videos using an Affective Multimodal Transformer model






Multi-Controlnet + consistency-decoder + INPAINTING + realestic-vision-v5 + Prompt-Weight + Single-Controlnet

controlnet-lineart-brightness-tile-inpainting + low res fix with tile

Mockup generator (bags, t-shirts, mugs, billboard etc) using Stable Diffusion in-painting



Fine-Tuned Vision Transformer (ViT) for NSFW Image Classification

Stable Diffusion XL + LCM + LoRa trained on images from Corning Museum of Glass (v1)



Create your own Realistic Voice Cloning (RVC v2) dataset using a YouTube link



Simple version of https://huggingface.co/teknium/OpenHermes-2-Mistral-7B

Very fast img2img for a collaboration with AI in real time












Source: NousResearch/Obsidian-3B-V0.5 ✦ Worlds smallest multi-modal LLM

Source: PocketDoc/Dans-AdventurousWinds-Mk2-7b ✦ Quant: TheBloke/Dans-AdventurousWinds-Mk2-7B-AWQ ✦ This model is proficient in crafting text-based adventure games
Source: Intel/neural-chat-7b-v3-1 ✦ Quant: TheBloke/neural-chat-7B-v3-1-AWQ ✦ Fine-tuned model based on mistralai/Mistral-7B-v0.1

Animate Your Personalized Text-to-Image Diffusion Models with SDXL and LCM

Text to video diffusion model with variable length frame conditioning for infinite length video

Dreamshaper-7 img2img with LCM LoRA for faster inference



An auto-regressive causal LM created by combining 2x finetuned Llama-2 70B into one.


RealvisXL-v2.0 with LCM LoRA - requires fewer steps (4 to 8 instead of the original 40 to 50)

Take a list of image URLs as frames and output a video