Explore
Featured models

black-forest-labs / flux-canny-pro
Professional edge-guided image generation. Control structure and composition using Canny edge detection

black-forest-labs / flux-fill-pro
Professional inpainting and outpainting model with state-of-the-art performance. Edit or extend images with natural, seamless results.

black-forest-labs / flux-1.1-pro-ultra
FLUX1.1 [pro] in ultra and raw modes. Images are up to 4 megapixels. Use raw mode for realism.

black-forest-labs / flux-redux-dev
Open-weight image variation model. Create new versions while preserving key elements of your original.

recraft-ai / recraft-v3
Recraft V3 (code-named red_panda) is a text-to-image model with the ability to generate long texts, and images in a wide list of styles. As of today, it is SOTA in image generation, proven by the Text-to-Image Benchmark by Artificial Analysis

davisbrown / flux-half-illustration
Flux lora, use "in the style of TOK" to trigger generation, creates half photo half illustrated elements
I want to…
Generate images
Models that generate images from text prompts
Use a language model
Models that can understand and generate text
Upscale images
Upscaling models that create high-quality images from low-quality images
Caption images
Models that generate text from images
The FLUX family of models
The FLUX family of text-to-image models from Black Forest Labs
Restore images
Models that improve or restore images by deblurring, colorization, and removing noise
Get embeddings
Models that generate embeddings from inputs
Extract text from images
Optical character recognition (OCR) and text extraction
Transcribe speech
Models that convert speech to text
Use handy tools
Toolbelt-type models for videos and images.
Chat with images
Ask language models about images
Edit images
Tools for manipulating images.
Use a face to make images
Make realistic images of people instantly
Flux fine-tunes
Browse the diverse range of fine-tunes the community has custom-trained on Replicate
Generate music
Models to generate and modify music
Generate videos
Models that create and edit videos
Generate speech
Convert text to speech
Make 3D stuff
Models that generate 3D objects, scenes, radiance fields, textures and multi-views.
Get structured data
Language models that support grammar-based decoding as well as jsonschema constraints.
Popular models

A simple OCR Model that can easily extract text from an image.

SDXL-Lightning by ByteDance: a fast text-to-image model that makes high-quality images in 4 steps

Fine-Tuned Vision Transformer (ViT) for NSFW Image Classification
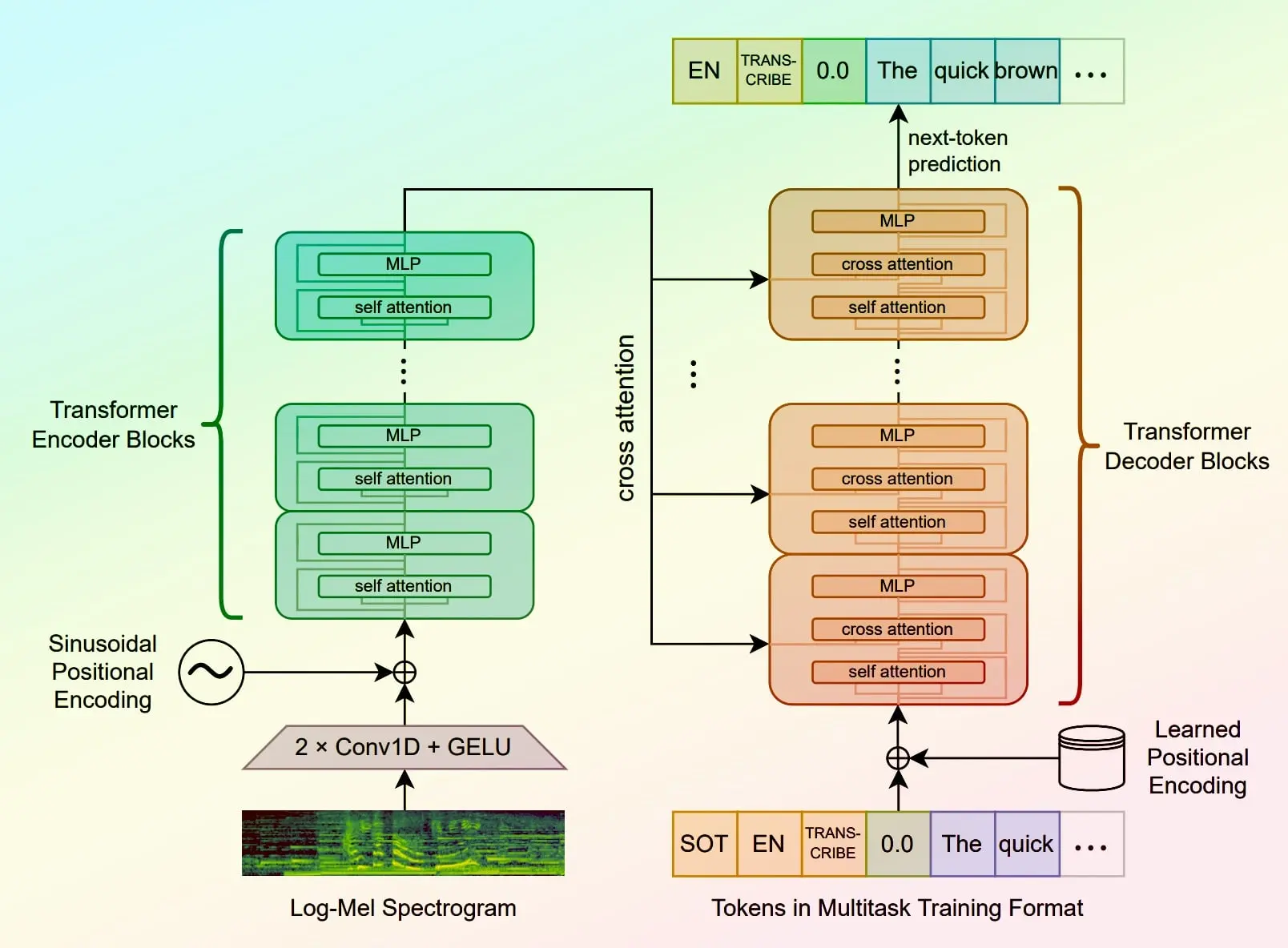



Return CLIP features for the clip-vit-large-patch14 model

Visual instruction tuning towards large language and vision models with GPT-4 level capabilities
Latest models

🎨AnimateDiff Prompt Travel🧭 Seamlessly Navigate and Animate Between Text-to-Image Prompts for Dynamic Visual Narratives
A simple OCR Model that can easily extract text from an image.





Synthesizing High-Resolution Images with Few-Step Inference


Tuning-free Higher-Resolution Visual Generation with Diffusion Models





MusicGen fine-tuned on Burt Bacharach's top hits







Marrying Pixel and Latent Diffusion Models for Text-to-Video Generation
Gender recognition for audio files



MusicGen fine-tuned on cover-songs by Toad from 'Super Mario' series. Text token : "by toad"





A multimodal LLM-based AI assistant, which is trained with alignment techniques. Qwen-VL-Chat supports more flexible interaction, such as multi-round question answering, and creative capabilities.


Mistral-7B-v0.1 fine tuned for chat with the OpenOrca dataset.




A high-performing language model trained to act as a helpful assistant

Controlling Vision-Language Models for Universal Image Restoration


✨DiffBIR: Towards Blind Image Restoration with Generative Diffusion Prior


